![]()
Haztrak is an overkill proof of concept (POC) project that illustrates how third party system can leverage the resources exposed by the U.S. Environmental Protection Agency's IT systems, RCRAInfo and e-Manifest. More specifically, how these resources can be leveraged to electronically manifest hazardous waste shipments to ensure proper management from cradle-to-grave instead of the manual and paper intensive process that has been in place since the 1980's.
Please keep in mind that Haztrak is labor of love, there's aspects of Haztrak that will likely never be ready for a production deployment. Our entire budget is our spare time.
Report an Issue or Ask Questions
See a mistake in this documentation? Have a suggestion or questions? Submit an issue to our issue tacker
About e-Manifest
June 30, 2018. the United States Environmental Protection Agency (USEPA or EPA) launched a national system for tracking hazardous waste shipments electronically, this system, known as "e-Manifest," modernizes the nation’s paper-intensive process for tracking hazardous waste from cradle to grave while saving valuable time, resources, and dollars for industry and states.
e-Manifest is a modular component of RCRAInfo which can be accessed by its users in two ways:
- Through their favorite web browser at https://rcrainfo.epa.gov/
- Via the RCRAInfo RESTful application programming interface (API)
Haztrak aims to serve as a reference implementation for how hazardous waste handlers can utilize the latter in their own waste management software.
This project would not be possible without the work of the EPA e-Manifest Team.
e-Manifest Documentation
To learn more about e-Manifest, visit the developer documentation in the USEPA/e-Manifest repository. You can also find more information on the e-Manifest homepage on recent regulatory and policy changes, webinars, user calls, and other resources.
Source Roadmap
We know that finding your way around a new codebase can be tough. This chapter will get you acquainted with the project and repository structure.
├── /configs : Example configuration to be passsed as environment variables
├── /docs : project written documentation
├── runhaz.sh : shell script for aiding local development
├── /client : Root for the single page application
│ ├── /...
│ ├── /public : public content and static assets
│ └── /src
│ ├── /components : React componets and building blocks
│ ├── /features : Higher level components
│ ├── /hooks : Custon hooks
│ ├── /services : Library for consuming web services
│ └── /store : Global store slices and logic
└── /server : Root for the Django http server
├── /core : features on the backend are split into 'django apps'
├── /site : e.g., the 'site' app encapsulates the TrakSite model, views, and logic
├── /... : More apps, excluded for brevity
├── /org : An app generally follow the pattern found in the django docs
│ ├── /migrations : Database migration
│ ├── /models : Entity/Model definitions for database persistence
│ ├── /serializers : Serializers for encoding Python objects (e.g., to JSON)
│ ├── /services : Business logic
│ ├── /tasks : Asynchronous tasks (e.g., used to interface with RCRAInfo)
│ ├── /tests : Tests specific to this django app
│ └── /views : Our Django (DRF) views
├── /fixtures : Initial data loaded on start for development
├── /haztrak : Backend configuration that glues everything together
└── ... : Configuration module
Notable Directories
Server
Notable directories for server development and source control
The Django Apps
server/
This directory houses all our Django apps (Django refers to each one of these as an 'app', not to be confused with the
smallest deployable unit which is a 'project', a project uses many apps). On many Django projects the apps would be in
the root of the project, we keep them in 'server' for organizational purposes.
Each app constitutes a vertical slice through our back end system.
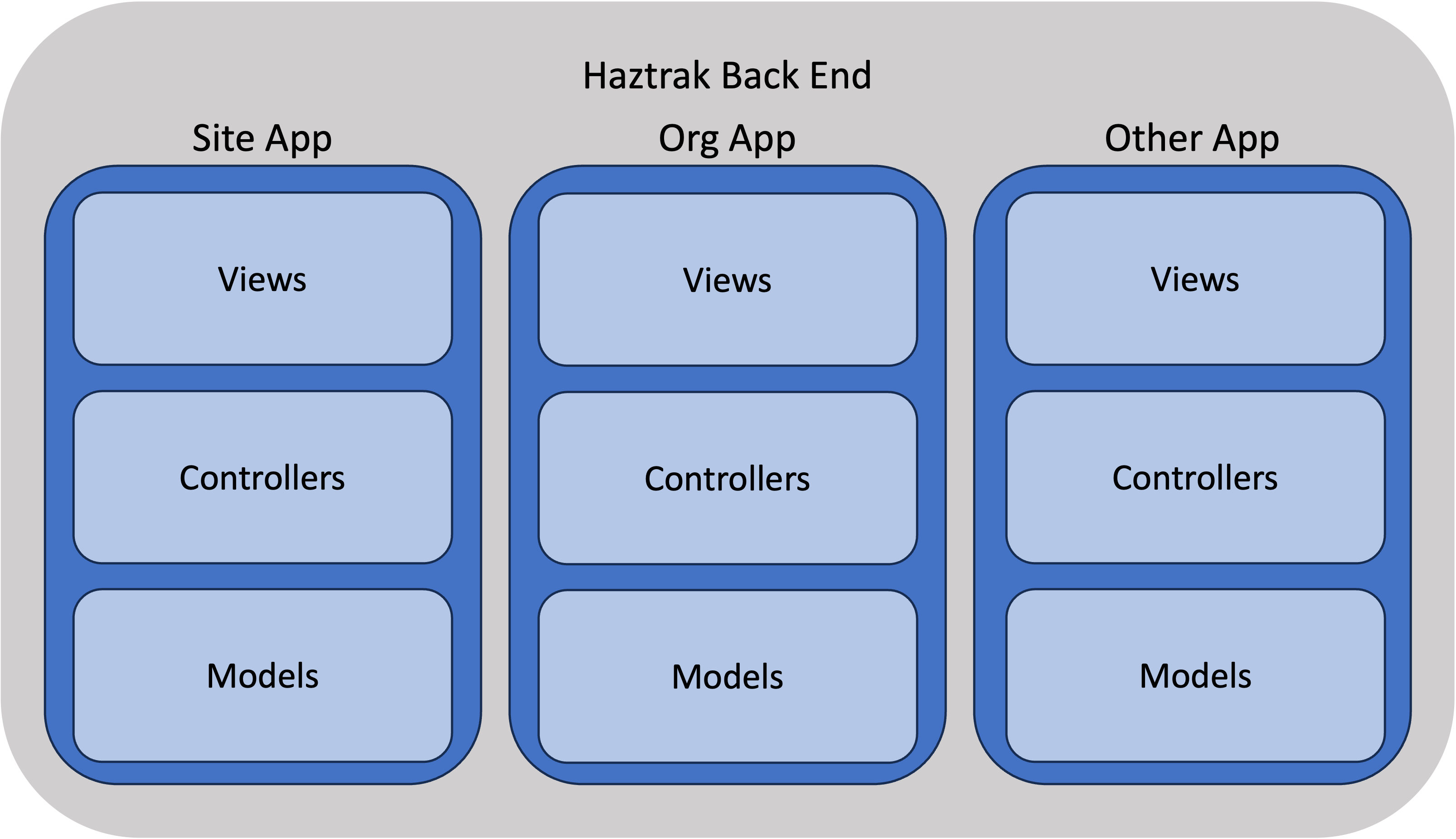
The Core App
server/core
This app contains our user model, authentication, and things that a used by many other apps.
Future work will remove unnecessary dependencies on this app from other apps.
The Site App
server/site
This app contains the TrakSite entity, views, and logic.
A TrakSite is a location that where EPA regulated activity occurs that our users work with.
Haztrak only supports working with regulated activities that fall under
regulations promulgated under the Resource Conservation and Recovery Act (RCRA),
Due to Haztrak's scope, a TrakSite will always have a RcraSite, but not always the other way around.
but theoretically, a TrakSite could also correspond to a location where other environmental
regulated activities occur such as Clean Air Act (CAA) or Clean Water Act (CWA) regulated activities.
The RCRASite App
server/rcrasite
This app contains the RcraSite models. A RcraSite is a location that is known to the EPA's RCRAInfo system.
The Org App
server/org
This app contains the TrakOrg (short for "Trak Organization") model, views, and logic.
A TrakOrg is an organization allows Haztrak to tie together users and sites.
An Org is managed by one or more admins, admins can control RBAC to TrakSites for the organization's users.
EPA's RCRAInfo system does not have a concept of an organization.
Client
Notable directories for client development and source control
Client Features
client/src/features
This directory, contains our features. Features consume components the redux store slices.
Generally, features map to routes the user can take.
A feature component only relies on global state/context and does not accept any props.
Client Components
client/src/components
This directory contains basic components that act as building blocks for features.
Ideally, components should be 'dumb', only consuming props and not relying on global state/context,
however we have not been strict about this. But please keep this in mind as this generally keeps
the component more testable, more focused, and easier to understand.
Components should be organized by concept, not by role (i.e., don't put all buttons in a Button directory).
The hierarchy of our component dependencies should generally follow a tree structure.
For example, if a MyManifest component depends on a ManifestGeneralDetails component, the ManifestGeneralDetails
be in the same directory or a subdirectory of the MyManifest component.
The corollary to this is the UI directory, which contains components that do not contain any logic, and are used by
any component in the application.
Source Roadmap
We know that finding your way around a new codebase can be tough. This chapter will get you acquainted with the project and repository structure.
├── /configs : Example configuration to be passsed as environment variables
├── /docs : project written documentation
├── runhaz.sh : shell script for aiding local development
├── /client : Root for the single page application
│ ├── /...
│ ├── /public : public content and static assets
│ └── /src
│ ├── /components : React componets and building blocks
│ ├── /features : Higher level components
│ ├── /hooks : Custon hooks
│ ├── /services : Library for consuming web services
│ └── /store : Global store slices and logic
└── /server : Root for the Django http server
├── /core : features on the backend are split into 'django apps'
├── /site : e.g., the 'site' app encapsulates the TrakSite model, views, and logic
├── /... : More apps, excluded for brevity
├── /org : An app generally follow the pattern found in the django docs
│ ├── /migrations : Database migration
│ ├── /models : Entity/Model definitions for database persistence
│ ├── /serializers : Serializers for encoding Python objects (e.g., to JSON)
│ ├── /services : Business logic
│ ├── /tasks : Asynchronous tasks (e.g., used to interface with RCRAInfo)
│ ├── /tests : Tests specific to this django app
│ └── /views : Our Django (DRF) views
├── /fixtures : Initial data loaded on start for development
├── /haztrak : Backend configuration that glues everything together
└── ... : Configuration module
Notable Directories
Server
Notable directories for server development and source control
The Django Apps
server/
This directory houses all our Django apps (Django refers to each one of these as an 'app', not to be confused with the
smallest deployable unit which is a 'project', a project uses many apps). On many Django projects the apps would be in
the root of the project, we keep them in 'server' for organizational purposes.
Each app constitutes a vertical slice through our back end system.
The Core App
server/core
This app contains our user model, authentication, and things that a used by many other apps.
Future work will remove unnecessary dependencies on this app from other apps.
The Site App
server/site
This app contains the TrakSite entity, views, and logic.
A TrakSite is a location that where EPA regulated activity occurs that our users work with.
Haztrak only supports working with regulated activities that fall under
regulations promulgated under the Resource Conservation and Recovery Act (RCRA),
Due to Haztrak's scope, a TrakSite will always have a RcraSite, but not always the other way around.
but theoretically, a TrakSite could also correspond to a location where other environmental
regulated activities occur such as Clean Air Act (CAA) or Clean Water Act (CWA) regulated activities.
The RCRASite App
server/rcrasite
This app contains the RcraSite models. A RcraSite is a location that is known to the EPA's RCRAInfo system.
The Org App
server/org
This app contains the TrakOrg (short for "Trak Organization") model, views, and logic.
A TrakOrg is an organization allows Haztrak to tie together users and sites.
An Org is managed by one or more admins, admins can control RBAC to TrakSites for the organization's users.
EPA's RCRAInfo system does not have a concept of an organization.
Client
Notable directories for client development and source control
Client Features
client/src/features
This directory, contains our features. Features consume components the redux store slices.
Generally, features map to routes the user can take.
A feature component only relies on global state/context and does not accept any props.
Client Components
client/src/components
This directory contains basic components that act as building blocks for features.
Ideally, components should be 'dumb', only consuming props and not relying on global state/context,
however we have not been strict about this. But please keep this in mind as this generally keeps
the component more testable, more focused, and easier to understand.
Components should be organized by concept, not by role (i.e., don't put all buttons in a Button directory).
The hierarchy of our component dependencies should generally follow a tree structure.
For example, if a MyManifest component depends on a ManifestGeneralDetails component, the ManifestGeneralDetails
be in the same directory or a subdirectory of the MyManifest component.
The corollary to this is the UI directory, which contains components that do not contain any logic, and are used by
any component in the application.
Authentication and Authorization
This project makes extensive use of the Django authentication and authorization system. This document does not provide a overview of Django's auth systems, for more information, see the Django documentation.
Authentication
This project makes use of Django's built-in authentication system django.contrib.auth and the
packages in the Django ecosystem (e.g., django-allauth, django-guardian).
We do not rely on external authentication services for this project to keep the project focused, avoid advertising a third-party service (as the U.S. government).
Authorization
Authorization is relatively complex for this project. Access to a resources (e.g., a manifest) is a dynamic process and needs to be determined on a per-user + per-role + per-object + per-object status basis.
As an example scenario, a user wants to edit a manifest. The following applies:
- The user must be authenticated.
- The user must have access to a site listed on the manifest.
- The user must have the appropriate role/permission to edit the manifest.
- The manifest must be in a status that allows editing.
- The specific edits must be allowed by e-Manifest.
Haztrak uses django-guardian for per-object permissions, to control site access and related
resources.
Source Design Document
This document's purpose is to outline Haztrak's system architecture and design. For more information on the project's specifications and requirements, see the Software Requirements Specification.
Architecture Overview
Haztrak follows is consist of a number of containerized components. The components that are deployed separately but closely work together. The overall system would be classified as a monolithic architecture however, certain components could be scaled independently (e.g., the number servers instances is separate from the front end), and newer versions of components could be deployed without affecting the entire system, given they do not introduce breaking changes. Nevertheless, the system is not designed to be categorized as microservices.
- A Server that exposes a RESTful API and a serv side rendered admin UI.
- A relational database.
- An in memory datastore
- A task queue
- A task scheduler
- A client side rendered user interface
Server and Rest API
The REST API is the primary way users read and change data in the Haztrak system. It is implemented using Python, the Django Framework, and Django Rest Framework.
The choice to use Python stemmed from a desire to use a language that the team was already familiar with, something that is easy to learn (regardless of whether Python is your primary language, it's easy to read). The choice to use Django was made because it is a mature, well-documented, and widely used framework that provides a lot of functionality out of the box.
Useful Links for Django architecture, the service layer, and more
in each Django app, you'll find a service package which encapsulates the domain logic.
Haztrak adopted this approach, for a couple reasons including:
- Ease of testing
- separation of concerns
- We subscribe to the belief that the view should be worried about just that, 'the representation'
- The model/active record approach leads to god classes that do too much
- A good place to place multimodel logic.
DjangoCon 2021 talk by Paul Wolf. Hack Soft Django Styleguide repo. Martin Fowler article on BoundedContext. Article on service layer by Martin Fowler. Against Service Layers in Django (reddit.com).
Admin Site
The admin interface is an out-of-the-box feature of
the Django framework.
It can be found by appending /admin to the URL of the host and port of HTTP
server, for example http://localhost/admin
In-memory Database
The in-memory data store serves a couple purposes,
- As a message broker for Haztrak's task queue
- A cache for the http server
As a cache, the in-memory data store is utilized to increase performance by allowing Haztrak to cut down on latency for recently used resources including recent database queries, computed values, and external service calls. As a message broker, the data store provides a reliable way for the back end service to communicate which each other (e.g., launch background tasks).
The Haztrak project currently uses Redis as both the message broker and in-memory data store.
Haztrak Client Architecture
Application Overview
The browser client is a single page application (SPA) that uses the React library and ecosystem to client side render the user interface. It is responsible for guiding the user during the creation, editing, and signing of electronic manifests.
Application Configuration
The project was originally bootstrapped with
Create React App but was transitioned to use the Vite
build tool. For more information on Vite, see the Vite documentation. The configuration is found in
./client/vite.config.ts.
The following tools have been configured to aid development:
ESLint
The project uses ESLint to lint the codebase and prevent developers from making common/easy to fix mistakes and enforce consistency. For more information on ESLint, see the ESLint documentation.
TypeScript
While ESLint is great for catching common little mistakes related to JavaScript, TypeScript is a superset of JavaScript that adds type checking. It's a great tool for catching more complex mistakes and preventing them from making it into production. For more information on TypeScript, see the TypeScript documentation. TypeScript is configured in
./client/tsconfig.json.
Prettier
Prettier is a tool for formatting. If enforces a consistent style across the entire codebase and amongst multiple developers, thereby making the codebase more readable and maintainable. For more information on Prettier, see the Prettier documentation.
Style Guide
Clean Code
A classic book on writing clean code is Clean Code: A Handbook of Agile Software Craftsmanship. It's a great read and highly recommended.
Naming Conventions
Haztrak recommends reading this naming convention guide hosted on github that (conveniently) uses javascript.
In addition, the project uses the following naming conventions for various items:
Selectors
Selectors are functions that take the state as an argument and return some data from the state. They are used to encapsulate the state shape and allow us to change the state shape without having to change all the places where we access the state.
We use two naming conventions for selectors:
<stateField>Selector
React Components
Constructors that return a React component should be named with PascalCase. (e.g.,
MyComponent). In addition, the file they are located in should also be named with PascalCase (e.g.,
MyComponent.tsx).
React features
Do differentiate between react components and features, we use lowercase directory name. These directories often do not export a named constant that is identical to the directory name.
import { ManifestDetails as Component } from './manifestDetails';
export { Component };
which will automatically be lazy loaded by the React router, which helps with code splitting and keeps are bundle sizes small.
Project Structure
See the source roadmap for a high level overview of the project structure.
State Management
Application State
The project employs Redux and
Redux toolkit as a global state management library. The store is the single source of truth for the client application and stores information relevant to all/most/many subcomponents in the application. For more information on redux, see the redux documentation.
Component State
The project uses the useState and
useReducer React hooks to manage component state. For more information on hooks, see the react documentation. This type of state is local to a component and can be passed down to child components via props or context.
Form State
The project embraces use of uncontrolled form inputs where possible. As such, the project uses the
react-hook-form library to manage form state. For more information on
react-hook-form, see the react-hook-form documentation.
Since the manifest is a relatively large and complex schema, we do need to use controlled components when necessary. For example, the hazardous waste generator's state, which is used in other parts of the manifest form to decide what state waste codes are available for selection. This state is controlled in the ManifestForm component and passed down to the child components that need it via props (e.g., the generator form and the waste line forms).
The
react-hook-form library facilitates the mechanism we use to add one-to-many relationships via the
useFieldArray hook. This allows us to add/edit/delete multiple waste lines and transporters to a manifest.
The forms are also integrated with a schema validation library, currently zod. This allows us to validate the form data before submitting it to the server. For more information on zod, see the zod documentation.
URL state
The project uses the
react-router library to manage URL state. For more information on
react-router, see the react-router documentation. Parameters are passed to components via the URL and are accessible via the
useParams hook which allows users to share URLs with other users and bookmark URLs for later use.
The complete URL tree can be viewed in the
routes.tsx file in the root of the client directory.
Testing
This project uses
vitest as the test runner as it integrates its configs seamlessly with the
vite build tool and exposes a
Jest compatible API (which is generally a standard in the javascript ecosystem). For more information on
vitest, see the vitest documentation.
Tooling
As previously mentioned the project uses
vitest. In addition, for assertions, the project uses the
react-testing-library library. For more information on
react-testing-library, see the react-testing-library documentation.
We also use
msw to mock API requests to ensure that test can be run offline with predictable results. For more information on
msw, see the msw documentation.
Unit Tests
Unit test represent the bulk of our tests. These test a single unit or component and ensure that it behaves as expected. Unit tests are located in the same directory as the component they are testing and are named with the
.spec.tsx extension.
Integration Tests
Integration test look similar to unit test, but they test multiple components simultaneously and ensure they interact as expected. Like unit tests, integration tests are located in the same directory as the component they are testing and are named with the
.spec.tsx extension.
With integration test, we primarily focus on testing behavior of components to ensure the user interface is behaving as expected. We do not test the implementation details of the components, such as the internal state of the component.
Database Design
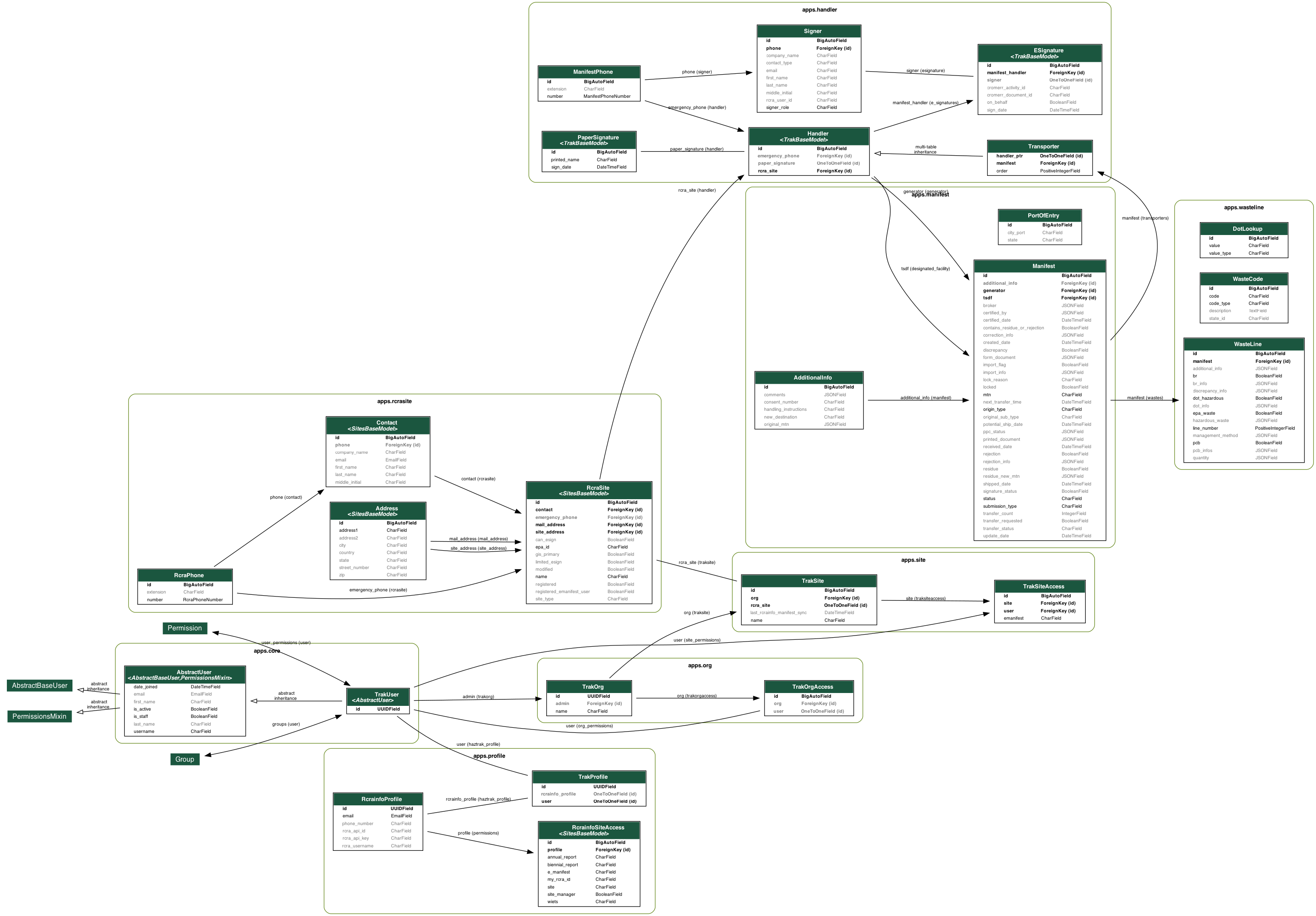
Overview
Haztrak depends on a relational database to persist its user data as well as information synced with (pulled from) RCRAInfo. RCRAInfo/e-Manifest should always be treated as the source of truth, however, the database provides users the means to, for example, draft or update electronic manifests without submitting the changes to RCRAInfo immediately.
The database schema is maintained in version control via a series of 'migration' scripts. This also enables haztrak to initiate a new database and scaffold the expected schema quickly and consistently for local development, testing, and backup.
The Haztrak project currently utilizes PostgreSQL, a widely used open-source object-relational database system known for reliability and performance.
Notes on generating the ERD
We use the pygraphviz python library and the django-extensions reusable Django app to generate the above entity relationship diagram (ERD).
Installing Header Files
This library doesn't come with pre-compiled wheels, so you'll need to install the C header files.
Fedora/RHEL
dnf install python3-devel graphviz-devel
Ubuntu/Debian
apt-get install libpython3-dev libgraphviz-dev
after installing the necessary header files, install the pygraphviz package from PyPI.
pip install pygraphviz
Generate the ERD
Use the runhaz.sh shell script to (re)generate the ERD.
It applies some default flags to the pygraphviv command to constrain and style
the ERD to fit our documentation needs.
Use ./runhaz.sh -h for help.
./runhaz.sh -e
Task Queue
The distributed task queue serves as Haztrak's way to ,asynchronously, perform operations that cannot give reasonable guarantees around the time necessary to complete. Sending computationally intensive or network dependant operation to the task queue allows Haztrak to remove long-lasting process from the HTTP request-response lifecycle to provide a 'smooth' user experience and allows haztrak to handle a higher volume of traffic.
For Haztrak, a large part of this is communicating with RCRAInfo via its web services
Implementation
Haztrak uses the Celery and Celery beat for asynchronous task management. Tasks can be scheduled to run at a specific time (via Celery Beat), or they can be triggered by events such as user actions or system events. Celery also provides support for task chaining and task result handling. Haztrak utilizes Redis as its Message Broker.
All tasks should be idempotent by design.
Task Results
Tasks results are persisted in Django's configured database, results can be viewed through the Django admin user interface. Please note that task results must be JSON serializable.
Testing
The Haztrak project uses a combination of manual and automated testing to ensure that the application is thoroughly tested.
Contributors are encouraged to practice test driven development (TDD), we often ask that contributors provide tests to prove their PR are acting as intended.
Testing the Server
The test suite for
each Django app
is located in the tests directory of each app.
test files are ignored during the container build process.
The following links provide a good overview of testing within the Django, and DRF, ecosystems.
Pytest and Fixtures
To get started writing test for the server, you will need to be familiar with pytest.
As part of the effort to reduce test maintenance cost, the haztrak project has
developed a series of
abstract factories as fixture. They are located in the conftest.py files,
which allows them to be
dependency injected into the test suite when requested by name.
For an introduction to using pytest fixtures to test django, see the following articles:
Running Server Tests
The client test suite can be run following these steps.
- set up your development environment, (e.g., clone the repo, setup a virtual environment)
- Clone the repo
- Create a virtual environment
- Activate the virtual environment
- Download the dependencies
- Run the tests
- To run all the test
pytest
- To run a specific test file or directory, just include the path to the test file or directory
pytest path/to/test.py
Testing the React Client
The Haztrak client employs an automated test suite with unit and integration tests to ensure the client is reliable and bug-free. These tests should be run locally by developers to ensure recent changes don't introduce errors as well during the CI process.
Tests are stored in *.spec.{ts,tsx} files alongside the corresponding source
file.
These files are ignored (not included) during the container build process.
Running Client Tests
The client test suite can be run following these steps.
- Setup the dev environment
- Clone the repo
- Change into the client directory
- Download the dependencies
-
configure the environment
cp ../configs/.env.test ./.env -
Run Tests
npm test
Local Development Environment
This chapter provides everything you need to know to set up a local development environment to work on Haztrak.
If you find something missing or inaccurate, please submit an issue here
Contents
- Set up with Docker Compose
- Fixtures
- Using RCRAInfo interfacing features
- Development Configs
- Developing without Docker
Docker Compose
- The easiest way to set up a local development environment is to
use docker compose
- You can use one of our config file to inject the environment variables needed to configure Haztrak ( see docker composes' documentation on environment files).
- You can either use the
--env-fileflag
docker compose --env-file configs/.env.dev up --build
or copy the config file to the project root as a .env file, modify it if
needed, and docker will apply it by default.
cp ./configs/.env.dev .env
docker compose up --build
You may find that after some changes (e.g., to the database) you need to
rebuild the containers
instead of restarting them.
In that case, use the --build flag, or you'll be running the last built image
instead of the
Dockerfile's build target
that we've specified in
the docker-compose.yaml
file.
After all containers are successfully running (you can inspect with
docker ps),
visit http://localhost
Fixtures (logging in)
- On start, fixtures will be loaded to the database, including 2 users to aid local development.
| username | password |
|---|---|
| testuser1 | password1 |
| admin | password1 |
- The admin user has superuser privileges and can also log in to the django admin portal.
Fixtures will also load a couple of sites.
VATESTGEN001- a preproduction site hazardous waste generatorMOCKTRANS001- a mock transporter siteMOCKTRANS002- a mock transporter siteMOCKTSDF001- a mock TSDF site
By Default, testuser1 only has access to VATESTGEN001, the mock sites can be
used to draft electronic manifests.
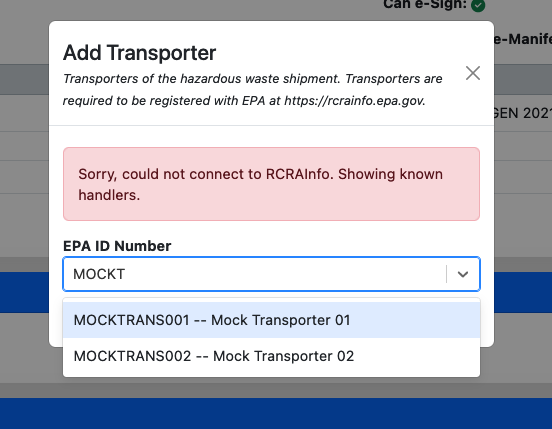
RCRAInfo API credentials
Haztrak's docker-compose file will load fixtures, however this data is limited. If you'd like to start using features that push/pull information from RCRAInfo/e-Manifest, you will need API credentials to the appropriate RCRAInfo deployment (e.g., ' preproduction').
For development, **ONLY USE THE PREPRODUCTION ** environment. See Haztrak's config documentation.
The general steps for obtaining an API ID and key (in preprod) are as follows.
- Register for an account in RCRAInfo (PreProduction)
- Request access to one fo the test site EPA IDs (e.g., VATESTGEN001)
- You'll need 'Site Manager' level access to obtain API credentials
- Await approval, or contact EPA via the "Feedback/Report an issue".
- Login after approval, generate your API Key.
For additional information on obtaining API credentials, see the USEPA/e-Manifest GitHub repository
Development Configs
Haztrak includes a couple configs to help ensure contributions use a consistent style guide. Most popular IDEs have a plugin to support these configs.
- pre-commit
- pre-commit hooks are set to run a number of linting and formatting checks before commits on any branch is accepted.
pip install -r server/requirements_dev.txt pre-commit install - .editorconfig
- Universal IDE configs for formatting files, most IDEs will have a plugin you can install that will apply these configs.
- runhaz.sh
- A bash script to help with development
- See usage with
$ ./runhaz.sh -h
- Prettier
- Prettier is used to autoformat source files, specifically the most of our non-python files. If you're using an IDE, it will likely have a prettier plugin available.
- The configs are found in .prettierrc.json and .prettierignore
- Black
- Black is a Python formatter from the Python Software Foundation. It's very opinionated and largely unconfigurable.
- Ruff
- ruff is a Python linter and (recently) formatter. It provides a fast and pleasant developer experience.
- MyPy
- Haztrak is (currently in the process) incrementally adopting type hints. MyPy is a static type checker for Python.
Local Development Without Docker
While it is possible, local development without containerization (docker) is not supported.
Local Development Environment
This chapter provides everything you need to know to set up a local development environment to work on Haztrak.
If you find something missing or inaccurate, please submit an issue here
Contents
- Set up with Docker Compose
- Fixtures
- Using RCRAInfo interfacing features
- Development Configs
- Developing without Docker
Docker Compose
- The easiest way to set up a local development environment is to
use docker compose
- You can use one of our config file to inject the environment variables needed to configure Haztrak ( see docker composes' documentation on environment files).
- You can either use the
--env-fileflag
docker compose --env-file configs/.env.dev up --build
or copy the config file to the project root as a .env file, modify it if
needed, and docker will apply it by default.
cp ./configs/.env.dev .env
docker compose up --build
You may find that after some changes (e.g., to the database) you need to
rebuild the containers
instead of restarting them.
In that case, use the --build flag, or you'll be running the last built image
instead of the
Dockerfile's build target
that we've specified in
the docker-compose.yaml
file.
After all containers are successfully running (you can inspect with
docker ps),
visit http://localhost
Fixtures (logging in)
- On start, fixtures will be loaded to the database, including 2 users to aid local development.
| username | password |
|---|---|
| testuser1 | password1 |
| admin | password1 |
- The admin user has superuser privileges and can also log in to the django admin portal.
Fixtures will also load a couple of sites.
VATESTGEN001- a preproduction site hazardous waste generatorMOCKTRANS001- a mock transporter siteMOCKTRANS002- a mock transporter siteMOCKTSDF001- a mock TSDF site
By Default, testuser1 only has access to VATESTGEN001, the mock sites can be
used to draft electronic manifests.
RCRAInfo API credentials
Haztrak's docker-compose file will load fixtures, however this data is limited. If you'd like to start using features that push/pull information from RCRAInfo/e-Manifest, you will need API credentials to the appropriate RCRAInfo deployment (e.g., ' preproduction').
For development, **ONLY USE THE PREPRODUCTION ** environment. See Haztrak's config documentation.
The general steps for obtaining an API ID and key (in preprod) are as follows.
- Register for an account in RCRAInfo (PreProduction)
- Request access to one fo the test site EPA IDs (e.g., VATESTGEN001)
- You'll need 'Site Manager' level access to obtain API credentials
- Await approval, or contact EPA via the "Feedback/Report an issue".
- Login after approval, generate your API Key.
For additional information on obtaining API credentials, see the USEPA/e-Manifest GitHub repository
Development Configs
Haztrak includes a couple configs to help ensure contributions use a consistent style guide. Most popular IDEs have a plugin to support these configs.
- pre-commit
- pre-commit hooks are set to run a number of linting and formatting checks before commits on any branch is accepted.
pip install -r server/requirements_dev.txt pre-commit install - .editorconfig
- Universal IDE configs for formatting files, most IDEs will have a plugin you can install that will apply these configs.
- runhaz.sh
- A bash script to help with development
- See usage with
$ ./runhaz.sh -h
- Prettier
- Prettier is used to autoformat source files, specifically the most of our non-python files. If you're using an IDE, it will likely have a prettier plugin available.
- The configs are found in .prettierrc.json and .prettierignore
- Black
- Black is a Python formatter from the Python Software Foundation. It's very opinionated and largely unconfigurable.
- Ruff
- ruff is a Python linter and (recently) formatter. It provides a fast and pleasant developer experience.
- MyPy
- Haztrak is (currently in the process) incrementally adopting type hints. MyPy is a static type checker for Python.
Local Development Without Docker
While it is possible, local development without containerization (docker) is not supported.
Continuous Integration (CI) - Continuous Delivery (CD)
CI Process
The CI process for Haztrak involves the following steps/aspects:
1. Source Control Management (SCM)
The project code is continually checked into a Git and stored on GitHub, which acts as the primary source control management system.
2. Automated Testing
The project has a suite of automated tests that are run on push to remote branches on GitHub. Test should be quick to run, and preferably only take seconds so can be run on a whim.
Code will not be merged into the main branch upstream (USEPA) until all tests pass.
3. Code Quality
The project uses common linting and formatting tools to ensure a base level of code quality. This is also checked before code is merged into the main branch. Code that does not pass linting and formatting test will not be merged into the main branch.
To ensure that code is linted and formatted, we recommend using the following tools:
See our contributing guide for more information on how to use these tools.
CD process
Haztrak serves as a reference implementation, it currently is not deployment to production (or any other deployment environment other than local development). So the extent of ouf continuous delivery (and deployment) process is limited to building OCI compliant container images and pushing them to the GitHub Container Registry (GCR).
Continuous Integration (CI) - Continuous Delivery (CD)
CI Process
The CI process for Haztrak involves the following steps/aspects:
1. Source Control Management (SCM)
The project code is continually checked into a Git and stored on GitHub, which acts as the primary source control management system.
2. Automated Testing
The project has a suite of automated tests that are run on push to remote branches on GitHub. Test should be quick to run, and preferably only take seconds so can be run on a whim.
Code will not be merged into the main branch upstream (USEPA) until all tests pass.
3. Code Quality
The project uses common linting and formatting tools to ensure a base level of code quality. This is also checked before code is merged into the main branch. Code that does not pass linting and formatting test will not be merged into the main branch.
To ensure that code is linted and formatted, we recommend using the following tools:
See our contributing guide for more information on how to use these tools.
CD process
Haztrak serves as a reference implementation, it currently is not deployment to production (or any other deployment environment other than local development). So the extent of ouf continuous delivery (and deployment) process is limited to building OCI compliant container images and pushing them to the GitHub Container Registry (GCR).
Configuration
Table of Contents
Overview
haztrak expects configurations in form of environment variables supplied at runtime, Yay! For non-containerized local development, you can place '.env' files in the server and client directories, with the outlined values below and the values will be automatically added. You can find example configs here.
Haztrak also comes with Dockerfiles and a docker-compose files, including docker-compose.yaml. Environment variables can be passed to a using docker-composes --env-file flag like so.
docker-compose --env-file configs/.env.dev up --build
Server
Required (server)
The follow variables are required, haztrak will exit if not present.
HT_SECRET_KEY: Salt for cryptographic hashing,
required by Django
Optional (server)
HT_DEBUG- Value:
TrueorFalse - Default:
False
- Value:
HT_HOST- Value: host/domain names that Django will serve
- Default: ['localhost']
- Description: the URL that the server will serve from,
see Django's ALLOWED_HOSTS documentation
- Haztrak currently only accepts one value
HT_TIMEZONE- Value: one of the approved names from the TZ Database list
- Default: 'UTC'
- Description: see Django's documentation
on TIME_ZONE
- In the future,
USE_TZwill be enabled by default
- In the future,
HT_RCRAINFO_ENV- Value:
preprod,prod, or the base url of the target RCRAInfo environment - Default:
preprod(for now in the current development phase) - Description: RCRAInfo environment that Haztrak will interface with per the e-Manifest API Client Library
- Value:
HT_CORS_DOMAIN- Value for cross-origin resource sharing, the domain that the React app is deployed
- Example for local development: should be something like
http://localhost:3000orhttp://localhost
HT_CACHE_URL- URL that points to the cache, in this instance Redis
- Example for local development: should be something like
redis://localhost:6379
Database
Technically these are optional. If these environment variables are not found, Haztrak will fall back to a SQLite3 database in the server directory, which may not be recommended for production, but this is an example web application.
HT_DB_ENGINE- The server driver
used by
django's ORM (e.g.,
django.db.backends.postgresql_psycopg2) - default:
django.db.backends.sqlite3
- The server driver
used by
django's ORM (e.g.,
HT_DB_NAME- default:
db.sqlite3
- default:
HT_DB_USER- default:
user
- default:
HT_DB_PASSWORD- default:
password
- default:
HT_DB_HOST- default:
localhost
- default:
HT_DB_PORT- default:
5432 - default for postgres is 5342
- default:
HT_TEST_DB_NAME- Name of database used for testing
defaults to
testif not present
- Name of database used for testing
defaults to
Celery
Haztrak offloads expensive tasks to a task queue, Celery. It requires access to a message broker like Redis or RabbitMQ.
CELERY_BROKER_URL- default:
redis://localhost:6379
- default:
CELERY_RESULT_BACKEND- default:
redis://localhost:6379
- default:
Logging
These configurations control the format and level of logging for our task queue and http server.
HT_LOG_FORMAT- Value: string corresponding to a formatter,
simple,verbose,superverbose. Seeserver/haztrak/settings.pyLOGGING section for details. - default:
verbose
- Value: string corresponding to a formatter,
logging can be filtered to only include logs that exceed a threshold. We use the python standard library logging module, levels can be found in their documentation here https://docs.python.org/3/library/logging.html#logging-levels
HT_LOG_LEVEL- default:
INFO
- default:
CELERY_LOG_LEVEL- default:
INFO
- default:
Client
Required (client)
VITE_HT_API_URL- Value: host/domain name of the haztrak back end
- Default:
http://localhost
VITE_HT_ENV- Default:
PROD - Options:
PROD,DEV,TEST - Description: The deployment environments,
TESTmock service worker that intercepts API calls and responds with test data. It can be used for testing, but also to develop the React client without the django server, however it is feature incomplete.
- Default:
Configuration
Table of Contents
Overview
haztrak expects configurations in form of environment variables supplied at runtime, Yay! For non-containerized local development, you can place '.env' files in the server and client directories, with the outlined values below and the values will be automatically added. You can find example configs here.
Haztrak also comes with Dockerfiles and a docker-compose files, including docker-compose.yaml. Environment variables can be passed to a using docker-composes --env-file flag like so.
docker-compose --env-file configs/.env.dev up --build
Server
Required (server)
The follow variables are required, haztrak will exit if not present.
HT_SECRET_KEY: Salt for cryptographic hashing,
required by Django
Optional (server)
HT_DEBUG- Value:
TrueorFalse - Default:
False
- Value:
HT_HOST- Value: host/domain names that Django will serve
- Default: ['localhost']
- Description: the URL that the server will serve from,
see Django's ALLOWED_HOSTS documentation
- Haztrak currently only accepts one value
HT_TIMEZONE- Value: one of the approved names from the TZ Database list
- Default: 'UTC'
- Description: see Django's documentation
on TIME_ZONE
- In the future,
USE_TZwill be enabled by default
- In the future,
HT_RCRAINFO_ENV- Value:
preprod,prod, or the base url of the target RCRAInfo environment - Default:
preprod(for now in the current development phase) - Description: RCRAInfo environment that Haztrak will interface with per the e-Manifest API Client Library
- Value:
HT_CORS_DOMAIN- Value for cross-origin resource sharing, the domain that the React app is deployed
- Example for local development: should be something like
http://localhost:3000orhttp://localhost
HT_CACHE_URL- URL that points to the cache, in this instance Redis
- Example for local development: should be something like
redis://localhost:6379
Database
Technically these are optional. If these environment variables are not found, Haztrak will fall back to a SQLite3 database in the server directory, which may not be recommended for production, but this is an example web application.
HT_DB_ENGINE- The server driver
used by
django's ORM (e.g.,
django.db.backends.postgresql_psycopg2) - default:
django.db.backends.sqlite3
- The server driver
used by
django's ORM (e.g.,
HT_DB_NAME- default:
db.sqlite3
- default:
HT_DB_USER- default:
user
- default:
HT_DB_PASSWORD- default:
password
- default:
HT_DB_HOST- default:
localhost
- default:
HT_DB_PORT- default:
5432 - default for postgres is 5342
- default:
HT_TEST_DB_NAME- Name of database used for testing
defaults to
testif not present
- Name of database used for testing
defaults to
Celery
Haztrak offloads expensive tasks to a task queue, Celery. It requires access to a message broker like Redis or RabbitMQ.
CELERY_BROKER_URL- default:
redis://localhost:6379
- default:
CELERY_RESULT_BACKEND- default:
redis://localhost:6379
- default:
Logging
These configurations control the format and level of logging for our task queue and http server.
HT_LOG_FORMAT- Value: string corresponding to a formatter,
simple,verbose,superverbose. Seeserver/haztrak/settings.pyLOGGING section for details. - default:
verbose
- Value: string corresponding to a formatter,
logging can be filtered to only include logs that exceed a threshold. We use the python standard library logging module, levels can be found in their documentation here https://docs.python.org/3/library/logging.html#logging-levels
HT_LOG_LEVEL- default:
INFO
- default:
CELERY_LOG_LEVEL- default:
INFO
- default:
Client
Required (client)
VITE_HT_API_URL- Value: host/domain name of the haztrak back end
- Default:
http://localhost
VITE_HT_ENV- Default:
PROD - Options:
PROD,DEV,TEST - Description: The deployment environments,
TESTmock service worker that intercepts API calls and responds with test data. It can be used for testing, but also to develop the React client without the django server, however it is feature incomplete.
- Default:
Containerization
This chapter provides some notes on our containerization strategy and using related tools with this project.
For more information on using Docker for local development, see Local Development.
Goals
The primary goals of the containerization strategy for Haztrak are:
- Ensuring consistent and reproducible deployments across different environments.
- Simplifying the development and testing processes by encapsulating application dependencies.
- Enabling scalability and flexibility to handle varying workload demands.
- Facilitating continuous integration and deployment practices.
Technology Stack
The containerization strategy for Haztrak leverages the following technologies:
- Docker: Used to create lightweight and isolated containers that encapsulate the application and its dependencies.
- Docker Compose: Facilitates the orchestration of multiple containers to define and manage the entire application stack.
- Kubernetes: Provides a container orchestration platform for managing containerized applications in a scalable and resilient manner.
- Helm: Used for packaging and deploying the application as Helm charts, enabling efficient management and configuration of the application stack.
Docker
Docker is a tool that allows us to package an application with all of its dependencies into a standardized unit for running and distributing applications. If you're not familiar with Docker, we recommend you check out their getting started guide.
Dockerfiles
Haztrak uses Dockerfiles to build images for local development and deployment. The Dockerfiles are located in the client and server directories.
The Dockerfiles have multiple targets, which allow us to build images for different purposes without duplicating code (or multiple files).
dev- used for local developmentproduction- used for deploymentbuilder- used by the other targets as a preliminary step for building the images for deployment- not intended to be used directly by the users
For example, the django http server dev target builds the initial layers of the
image the same way as the production target, however it will start the
django manage.py runserver command instead of a production server.
The client Dockerfile has a similar strategy for local development.
Docker Compose
The docker-compose
file, found in the project root, is used for local development. It uses the dev targets of
the Dockerfiles to build the images and start the containers. It also starts a postgres
relational database service and a redis service.
Celery images
The Celery worker and beat scheduler use the same image as the server but are initiated with different (custom) django management command. This custom commands start the celery worker and beat scheduler and allow us to use django's hot reloading for local development.
For now this suffices, but we may want to consider using a separate image for the celery worker and scheduler, or removing autoreload in production-like deployments, later down the road.
The custom celery commands can be found in the server/apps/core/management/commands directory.
Kubernetes
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. If you're unfamiliar with Kubernetes, we recommend you check out their getting started guide.
Helm
Helm is a package manager for Kubernetes. It allows us to define, install, and upgrade applications deployed to Kubernetes. Helm uses a packaging format called charts, which are a collection of template (yaml) files that we can feed values to in order to facilitate the deployment/install/upgrade of a Haztrak deployment.
Deployment
 Warning
Warning
This document includes guidance on hosting Haztrak using various cloud service providers. The United States Environmental Protection Agency (EPA) does not endorse any cloud service provider mentioned in this documentation. EPA is not responsible for any costs incurred by a third party that chooses to host Haztrak.
If you're looking to contribute to the Haztrak project, see our documentation setting up a local development environment section.
Overview
Where applicable, the Haztrak project embraces a number of doctrines1 that are important to understand:
- The 12 Factor App
- A methodology for building modern, scalable, maintainable software-as-a-service applications
- DevOps
- An approach that combines software development (Dev) and IT operations (Ops), emphasizing collaboration and automation to deliver software faster and more reliably.
- Haztrak embraces the following DevOps practices:
- Infrastructure as Code
- Continuous Integration & Delivery
- Continuous Monitoring
- The GitOps operational framework
Tools Employed
Section Coming soon.
Infrastructure as Code (IaC)
Section Coming soon.
Continuous Deployment
Section Coming soon.
Example local k8 Deployment
Don't bother following this yet. This is a work in progress meant to document the steps.
As an example, you can deploy Haztrak to a local Minikube cluster. Minikube is a lightweight tool for creating a Kubernetes cluster on your local machine.
Prerequisites
Before proceeding, ensure the following prerequisites are installed:
Steps
To deploy Haztrak locally to a Minikube cluster, follow these steps:
-
Start Minikube: Open a terminal and start the Minikube cluster using the following command: This may take a few minutes, depending on your system.
minikube start -
Clone the Haztrak repository to you local machine and cd into the project root:
git clone https://github.com/USEPA/haztrak.git cd haztrak -
configure your minikube environment to use the docker daemon running on your local machine:
eval $(minikube docker-env) -
Build the docker images for the Haztrak services:
docker build -t haztrak-server --target production ./server -
Deploy Haztrak: Run the following Helm command to deploy Haztrak:
helm install haztrak ./haztrak-chartsThis installs the Haztrak charts and creates the necessary Kubernetes resources in your minikube cluster.
-
Access Haztrak with
minikube servicecommand:minikube service haztrak
This will open a browser to IP address created by the haztrak k8 service for your viewing pleasure.
1 This is a not 100% accurate since Haztrak will never be deployed, by the EPA, to a true production environment. Declaring that we embrace GitOps and continuous monitoring is a little like armchair quarterbacking. The Haztrak project implements these practices in our development process where we can.