Pensacola Bay FL - Detailed step-by-step
Standardize, clean and wrangle Water Quality Portal data in Pensacola and Perdido Bays into more analytic-ready formats using the harmonize_wq package
US EPA’s Water Quality Portal (WQP) aggregates water quality, biological, and physical data provided by many organizations and has become an essential resource with tools to query and retrieval data using python or R. Given the variety of data and variety of data originators, using the data in analysis often requires data cleaning to ensure it meets the required quality standards and data wrangling to get it in a more analytic-ready format. Recognizing the definition of analysis-ready varies depending on the analysis, the harmonixe_wq package is intended to be a flexible water quality specific framework to help:
Identify differences in data units (including speciation and basis)
Identify differences in sampling or analytic methods
Resolve data errors using transparent assumptions
Reduce data to the columns that are most commonly needed
Transform data from long to wide format
Domain experts must decide what data meets their quality standards for data comparability and any thresholds for acceptance or rejection.
Detailed step-by-step workflow
This example workflow takes a deeper dive into some of the expanded functionality to examine results for different water quality parameters in Pensacola and Perdido Bays
Install and import the required libraries
[1]:
import sys
#!python -m pip uninstall harmonize-wq --yes
#!python -m pip install harmonize-wq --yes
# Use pip to install the package from pypi or the latest from github
#!{sys.executable} -m pip install harmonize-wq
# For latest dev version
#!{sys.executable} -m pip install git+https://github.com/USEPA/harmonize-wq.git@new_release_0-3-8
[2]:
import dataretrieval.wqp as wqp
from harmonize_wq import wrangle
from harmonize_wq import location
from harmonize_wq import harmonize
from harmonize_wq import visualize
from harmonize_wq import clean
Download location data using dataretrieval
[3]:
# Read geometry for Area of Interest from geojson file url and plot
aoi_url = r'https://raw.githubusercontent.com/USEPA/harmonize-wq/main/harmonize_wq/tests/data/PPBays_NCCA.geojson'
aoi_gdf = wrangle.as_gdf(aoi_url).to_crs(epsg=4326) # already standard 4326
aoi_gdf.plot()
[3]:
<Axes: >
[4]:
# Note there are actually two polygons (one for each Bay)
aoi_gdf
# Spatial query parameters can be updated to run just one
bBox = wrangle.get_bounding_box(aoi_gdf)
# For only one bay, e.g., first is Pensacola Bay:
#bBox = wrangle.get_bounding_box(aoi_gdf, 0)
[5]:
# Build query with characteristicNames and the AOI extent
query = {'characteristicName': ['Phosphorus',
'Temperature, water',
'Depth, Secchi disk depth',
'Dissolved oxygen (DO)',
'Salinity',
'pH',
'Nitrogen',
'Conductivity',
'Organic carbon',
'Chlorophyll a',
'Turbidity',
'Sediment',
'Fecal Coliform',
'Escherichia coli']}
query['bBox'] = bBox
[6]:
# Query stations (can be slow)
stations, site_md = wqp.what_sites(**query)
[7]:
# Rows and columns for results
stations.shape
[7]:
(2934, 37)
[8]:
# First 5 rows
stations.head()
[8]:
| OrganizationIdentifier | OrganizationFormalName | MonitoringLocationIdentifier | MonitoringLocationName | MonitoringLocationTypeName | MonitoringLocationDescriptionText | HUCEightDigitCode | DrainageAreaMeasure/MeasureValue | DrainageAreaMeasure/MeasureUnitCode | ContributingDrainageAreaMeasure/MeasureValue | ... | AquiferName | LocalAqfrName | FormationTypeText | AquiferTypeName | ConstructionDateText | WellDepthMeasure/MeasureValue | WellDepthMeasure/MeasureUnitCode | WellHoleDepthMeasure/MeasureValue | WellHoleDepthMeasure/MeasureUnitCode | ProviderName | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USGS-AL | USGS Alabama Water Science Center | USGS-02376115 | ELEVENMILE CREEK NR WEST PENSACOLA, FL | Stream | NaN | 03140107 | 27.8 | sq mi | 27.8 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NWIS |
| 1 | USGS-AL | USGS Alabama Water Science Center | USGS-02377570 | STYX RIVER NEAR ELSANOR, AL. | Stream | NaN | 03140106 | 192.0 | sq mi | 192.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NWIS |
| 2 | USGS-AL | USGS Alabama Water Science Center | USGS-02377920 | BLACKWATER RIVER AT US HWY 90 NR ROBERTSDALE, AL. | Stream | NaN | 03140106 | 23.1 | sq mi | 23.1 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NWIS |
| 3 | USGS-AL | USGS Alabama Water Science Center | USGS-02377960 | BLACKWATER RIVER AT CO RD 87 NEAR ELSANOR, AL. | Stream | NaN | 03140106 | 56.6 | sq mi | 56.6 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NWIS |
| 4 | USGS-AL | USGS Alabama Water Science Center | USGS-02377975 | BLACKWATER RIVER ABOVE SEMINOLE AL | Stream | NaN | 03140106 | 40.2 | sq mi | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NWIS |
5 rows × 37 columns
[9]:
# Columns used for an example row
stations.iloc[0][['HorizontalCoordinateReferenceSystemDatumName', 'LatitudeMeasure', 'LongitudeMeasure']]
[9]:
HorizontalCoordinateReferenceSystemDatumName NAD83
LatitudeMeasure 30.498252
LongitudeMeasure -87.335809
Name: 0, dtype: object
[10]:
# Harmonize location datums to 4326 (Note we keep intermediate columns using intermediate_columns=True)
stations_gdf = location.harmonize_locations(stations, out_EPSG=4326, intermediate_columns=True)
[11]:
location.harmonize_locations?
[12]:
# Rows and columns for results after running the function (5 new columns, only 2 new if intermediate_columns=False)
stations_gdf.shape
[12]:
(2934, 42)
[13]:
# Example results for the new columns
stations_gdf.iloc[0][['geom_orig', 'EPSG', 'QA_flag', 'geom', 'geometry']]
[13]:
geom_orig (-87.3358086, 30.49825159)
EPSG 4269.0
QA_flag <NA>
geom POINT (-87.3358086 30.49825159)
geometry POINT (-87.3358086 30.49825159)
Name: 0, dtype: object
[14]:
# geom and geometry look the same but geometry is a special datatype
stations_gdf['geometry'].dtype
[14]:
<geopandas.array.GeometryDtype at 0x7f4e8ffc1810>
[15]:
# Look at the different QA_flag flags that have been assigned,
# e.g., for bad datums or limited decimal precision
set(stations_gdf.loc[stations_gdf['QA_flag'].notna()]['QA_flag'])
[15]:
{'HorizontalCoordinateReferenceSystemDatumName: Bad datum OTHER, EPSG:4326 assumed',
'HorizontalCoordinateReferenceSystemDatumName: Bad datum UNKWN, EPSG:4326 assumed',
'LatitudeMeasure: Imprecise: lessthan3decimaldigits',
'LatitudeMeasure: Imprecise: lessthan3decimaldigits; HorizontalCoordinateReferenceSystemDatumName: Bad datum UNKWN, EPSG:4326 assumed',
'LatitudeMeasure: Imprecise: lessthan3decimaldigits; LongitudeMeasure: Imprecise: lessthan3decimaldigits',
'LongitudeMeasure: Imprecise: lessthan3decimaldigits',
'LongitudeMeasure: Imprecise: lessthan3decimaldigits; HorizontalCoordinateReferenceSystemDatumName: Bad datum UNKWN, EPSG:4326 assumed'}
[16]:
# Map it
stations_gdf.plot()
[16]:
<Axes: >
[17]:
# Clip to area of interest
stations_clipped = wrangle.clip_stations(stations_gdf, aoi_gdf)
[18]:
# Map it
stations_clipped.plot()
[18]:
<Axes: >
[19]:
# How many stations now?
len(stations_clipped)
[19]:
1473
[20]:
# To save the results to a shapefile
#import os
#path = '' #specify the path (folder/directory) to save it to
#stations_clipped.to_file(os.path.join(path, 'PPBEP_stations.shp'))
Retrieve Characteristic Data
[21]:
# Now query for results
query['dataProfile'] = 'narrowResult'
res_narrow, md_narrow = wqp.get_results(**query)
[22]:
df = res_narrow
df
[22]:
| OrganizationIdentifier | OrganizationFormalName | ActivityIdentifier | ActivityStartDate | ActivityStartTime/Time | ActivityStartTime/TimeZoneCode | MonitoringLocationIdentifier | ResultIdentifier | DataLoggerLine | ResultDetectionConditionText | ... | ResultDetectionQuantitationLimitUrl | LaboratoryAccreditationIndicator | LaboratoryAccreditationAuthorityName | TaxonomistAccreditationIndicator | TaxonomistAccreditationAuthorityName | LabSamplePreparationUrl | ProviderName | ActivityStartDateTime | AnalysisStartDateTime | AnalysisEndDateTime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USGS-FL | USGS Florida Water Science Center | nwisfl.01.95800571 | 1958-01-14 | 07:30:00 | EST | USGS-02376100 | NWIS-6891366 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NWIS | 1958-01-14 12:30:00+00:00 | NaT | NaT |
| 1 | USGS-FL | USGS Florida Water Science Center | nwisfl.01.95800571 | 1958-01-14 | 07:30:00 | EST | USGS-02376100 | NWIS-6891370 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NWIS | 1958-01-14 12:30:00+00:00 | NaT | NaT |
| 2 | USGS-FL | USGS Florida Water Science Center | nwisfl.01.95800572 | 1958-01-14 | 09:20:00 | CST | USGS-02376108 | NWIS-6891392 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NWIS | 1958-01-14 15:20:00+00:00 | NaT | NaT |
| 3 | USGS-FL | USGS Florida Water Science Center | nwisfl.01.95800572 | 1958-01-14 | 09:20:00 | CST | USGS-02376108 | NWIS-6891396 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NWIS | 1958-01-14 15:20:00+00:00 | NaT | NaT |
| 4 | USGS-FL | USGS Florida Water Science Center | nwisfl.01.95800639 | 1958-01-24 | 11:30:00 | CST | USGS-302646087122701 | NWIS-6891596 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NWIS | 1958-01-24 17:30:00+00:00 | NaT | NaT |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 420456 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_1_19680803_1415864 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_1 | STORET-742739949 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | STORET | NaT | NaT | NaT |
| 420457 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_S_19680803_1415863 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_S | STORET-742740047 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | STORET | NaT | NaT | NaT |
| 420458 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415874 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740009 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | STORET | NaT | NaT | NaT |
| 420459 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415872 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740002 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | STORET | NaT | NaT | NaT |
| 420460 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415873 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740006 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | STORET | NaT | NaT | NaT |
420461 rows × 81 columns
[23]:
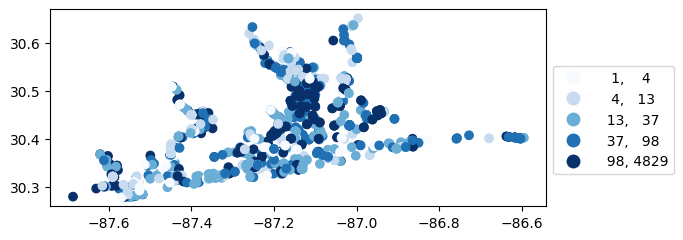
# Map number of usable results at each station
gdf_count = visualize.map_counts(df, stations_clipped)
legend_kwds = {"fmt": "{:.0f}", 'bbox_to_anchor':(1, 0.75)}
gdf_count.plot(column='cnt', cmap='Blues', legend=True, scheme='quantiles', legend_kwds=legend_kwds)
[23]:
<Axes: >
Harmonize Characteristic Results
Two options for functions to harmonize characteristics: harmonize_all() or harmonize_generic(). harmonize_all runs functions on all characteristics and lets you specify how to handle errors harmonize_generic runs functions only on the characteristic specified with char_val and lets you also choose output units, to keep intermediate columns and to do a quick report summarizing changes.
[24]:
# See Documentation
#harmonize.harmonize_all?
#harmonize.harmonize?
secchi disk depth
[25]:
# Each harmonize function has optional params, e.g., char_val is the characticName column value to use so we can send the entire df.
# Optional params: units='m', char_val='Depth, Secchi disk depth', out_col='Secchi', report=False)
# We start by demonstrating on secchi disk depth (units default to m, keep intermediate fields, see report)
df = harmonize.harmonize(df, 'Depth, Secchi disk depth', intermediate_columns=True, report=True)
-Usable results-
count 19538.000000
mean 1.166685
std 2.026694
min 0.000000
25% 0.600000
50% 1.000000
75% 1.400000
max 260.000000
dtype: float64
Unusable results: 88
Usable results with inferred units: 0
Results outside threshold (0.0 to 13.326848): 1
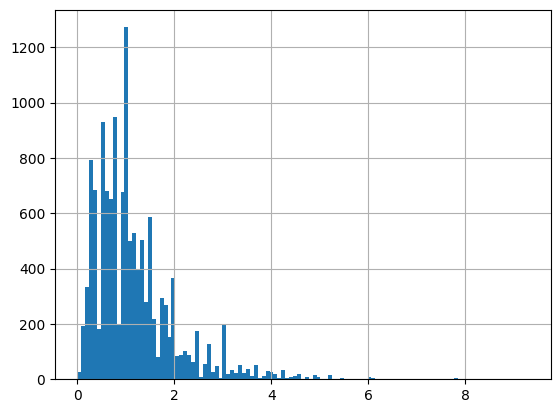
The threshold is based on standard deviations and is currently only used in the histogram.
[26]:
# Look at a table of just Secchi results and focus on subset of columns
cols = ['MonitoringLocationIdentifier', 'ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Units']
sechi_results = df.loc[df['CharacteristicName']=='Depth, Secchi disk depth', cols + ['Secchi']]
sechi_results
[26]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Units | Secchi | |
|---|---|---|---|---|---|---|
| 1932 | FWCLOCAL-03140105-ER-01 | 0.46 | m | <NA> | m | 0.46 meter |
| 1938 | FWCLOCAL-03140305-ER-02 | 0.61 | m | <NA> | m | 0.61 meter |
| 1943 | FWCLOCAL-03140305-ER-03 | 0.71 | m | <NA> | m | 0.71 meter |
| 1950 | FWCLOCAL-03140305-ER-05 | 0.79 | m | <NA> | m | 0.79 meter |
| 1951 | FWCLOCAL-03140305-ER-04 | 0.71 | m | <NA> | m | 0.71 meter |
| ... | ... | ... | ... | ... | ... | ... |
| 420071 | FWCLOCAL-03140305-ER-05 | 0.84 | m | <NA> | m | 0.84 meter |
| 420078 | FWCLOCAL-03140305-ER-02 | 0.84 | m | <NA> | m | 0.84 meter |
| 420113 | FWCLOCAL-03140305-ER-03 | 0.91 | m | <NA> | m | 0.91 meter |
| 420120 | FWCLOCAL-03140305-ER-05 | 0.81 | m | <NA> | m | 0.81 meter |
| 420132 | FWCLOCAL-03140305-ER-02 | 0.61 | m | <NA> | m | 0.61 meter |
19626 rows × 6 columns
[27]:
# Look at unusable(NAN) results
sechi_results.loc[df['Secchi'].isna()]
[27]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Units | Secchi | |
|---|---|---|---|---|---|---|
| 84136 | 21FLPNS_WQX-3302M13G | *Not Reported | m | ResultMeasureValue: "*Not Reported" result can... | m | NaN |
| 321458 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 321459 | 21FLKWAT_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 323047 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 323048 | 21FLKWAT_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| ... | ... | ... | ... | ... | ... | ... |
| 372535 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 373655 | 21FLCBA_WQX-OKA-CB-BASS-2 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 375998 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
| 381434 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
| 382500 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
88 rows × 6 columns
[28]:
# look at the QA flag for first row from above
list(sechi_results.loc[df['Secchi'].isna()]['QA_flag'])[0]
[28]:
'ResultMeasureValue: "*Not Reported" result cannot be used'
[29]:
# All cases where there was a QA flag
sechi_results.loc[df['QA_flag'].notna()]
[29]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Units | Secchi | |
|---|---|---|---|---|---|---|
| 84136 | 21FLPNS_WQX-3302M13G | *Not Reported | m | ResultMeasureValue: "*Not Reported" result can... | m | NaN |
| 321458 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 321459 | 21FLKWAT_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 323047 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 323048 | 21FLKWAT_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| ... | ... | ... | ... | ... | ... | ... |
| 372535 | 21FLCBA_WQX-OKA-CB-BASS-1 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 373655 | 21FLCBA_WQX-OKA-CB-BASS-2 | Not Reported | NaN | ResultMeasureValue: "Not Reported" result cann... | m | NaN |
| 375998 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
| 381434 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
| 382500 | 21FLKWAT_WQX-OKA-CB-BASS-2 | Not Reported | ft | ResultMeasureValue: "Not Reported" result cann... | ft | NaN |
88 rows × 6 columns
If both value and unit are missing nothing can be done, a unitless (NaN) value is assumed as to be in default units but a QA_flag is added
[30]:
# Aggregate Secchi data by station
visualize.station_summary(sechi_results, 'Secchi')
[30]:
| MonitoringLocationIdentifier | cnt | mean | |
|---|---|---|---|
| 0 | 11NPSWRD_WQX-GUIS_CMP_PKT01 | 12 | 2.333333 |
| 1 | 11NPSWRD_WQX-GUIS_CMP_PKT02 | 17 | 2.411765 |
| 2 | 11NPSWRD_WQX-GUIS_CMP_PKT03 | 3 | 2.333333 |
| 3 | 21AWIC-1063 | 124 | 0.775726 |
| 4 | 21AWIC-1122 | 64 | 2.981156 |
| ... | ... | ... | ... |
| 1168 | NARS_WQX-NCCA10-1432 | 1 | 1.075000 |
| 1169 | NARS_WQX-NCCA10-1433 | 1 | 1.423333 |
| 1170 | NARS_WQX-NCCA10-1434 | 1 | 2.400000 |
| 1171 | NARS_WQX-NCCA10-1488 | 1 | 0.736667 |
| 1172 | NARS_WQX-NCCA10-2432 | 1 | 1.600000 |
1173 rows × 3 columns
[31]:
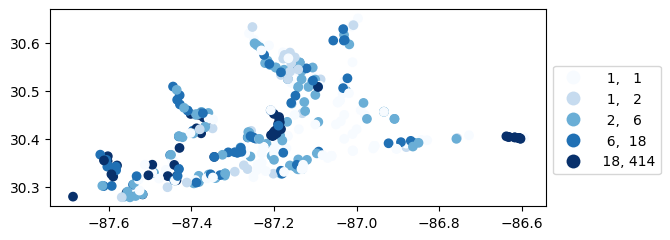
# Map number of usable results at each station
gdf_count = visualize.map_counts(sechi_results, stations_clipped)
gdf_count.plot(column='cnt', cmap='Blues', legend=True, scheme='quantiles', legend_kwds=legend_kwds)
[31]:
<Axes: >
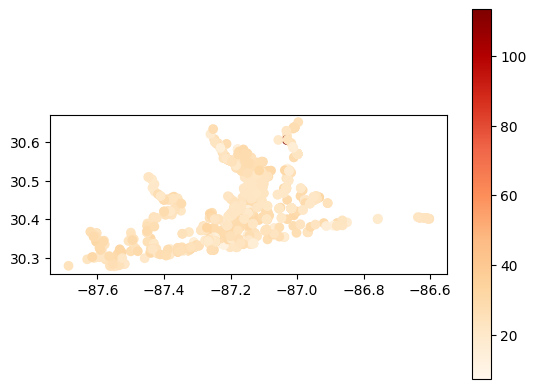
[32]:
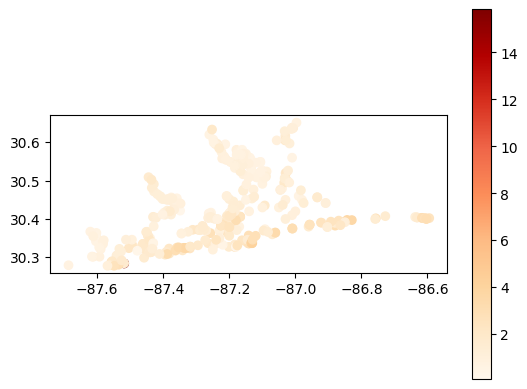
# Map average secchi depth results at each station
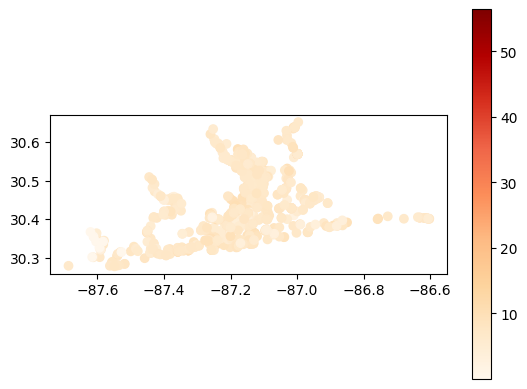
gdf_avg = visualize.map_measure(sechi_results, stations_clipped, 'Secchi')
gdf_avg.plot(column='mean', cmap='OrRd', legend=True)
[32]:
<Axes: >
Temperature
The default error=’raise’, makes it so that there is an error when there is a dimensionality error (i.e. when units can’t be converted). Here we would get the error: DimensionalityError: Cannot convert from ‘count’ (dimensionless) to ‘degree_Celsius’ ([temperature])
[33]:
#'Temperature, water'
# errors=‘ignore’, invalid dimension conversions will return the NaN.
df = harmonize.harmonize(df, 'Temperature, water', intermediate_columns=True, report=True, errors='ignore')
-Usable results-
count 94894.000000
mean 22.051910
std 9.858034
min -12.944444
25% 17.100000
50% 22.300000
75% 27.200000
max 1876.000000
dtype: float64
Unusable results: 2
Usable results with inferred units: 10
Results outside threshold (0.0 to 81.200116): 10
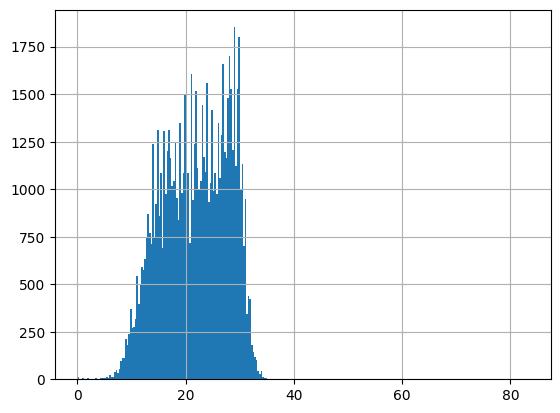
[34]:
# Look at what was changed
cols = ['MonitoringLocationIdentifier', 'ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Temperature', 'Units']
temperature_results = df.loc[df['CharacteristicName']=='Temperature, water', cols]
temperature_results
[34]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Temperature | Units | |
|---|---|---|---|---|---|---|
| 0 | USGS-02376100 | 13.9 | deg C | <NA> | 13.9 degree_Celsius | degC |
| 2 | USGS-02376108 | 24.4 | deg C | <NA> | 24.4 degree_Celsius | degC |
| 7 | USGS-02376700 | 21.1 | deg C | <NA> | 21.1 degree_Celsius | degC |
| 8 | USGS-02376100 | 22.8 | deg C | <NA> | 22.8 degree_Celsius | degC |
| 10 | USGS-02376108 | 32.8 | deg C | <NA> | 32.8 degree_Celsius | degC |
| ... | ... | ... | ... | ... | ... | ... |
| 420449 | 11NPSWRD_WQX-GUIS_FTPICKNS_1 | 16.1 | deg C | <NA> | 16.1 degree_Celsius | degC |
| 420452 | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | 29.1 | deg C | <NA> | 29.1 degree_Celsius | degC |
| 420453 | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | 20.1 | deg C | <NA> | 20.1 degree_Celsius | degC |
| 420457 | 11NPSWRD_WQX-GUIS_FTPICKNS_S | 28.6 | deg C | <NA> | 28.6 degree_Celsius | degC |
| 420459 | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | 27.9 | deg C | <NA> | 27.9 degree_Celsius | degC |
94896 rows × 6 columns
In the above we can see examples where the results were in deg F and in the result field they’ve been converted into degree_Celsius
[35]:
# Examine missing units
temperature_results.loc[df['ResultMeasure/MeasureUnitCode'].isna()]
[35]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Temperature | Units | |
|---|---|---|---|---|---|---|
| 145257 | 21FLCBA-FWB01 | 71.2 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 71.2 degree_Celsius | degC |
| 145259 | 21FLCBA-FWB01 | 83.3 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 83.3 degree_Celsius | degC |
| 145263 | 21FLCBA-FWB02 | 82.6 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 82.6 degree_Celsius | degC |
| 145266 | 21FLCBA-FWB02 | 71.8 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 71.8 degree_Celsius | degC |
| 145281 | 21FLCBA-FWB02 | 82.1 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 82.1 degree_Celsius | degC |
| 145286 | 21FLCBA-FWB02 | 79.4 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 79.4 degree_Celsius | degC |
| 145295 | 21FLCBA-FWB05 | 81.7 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 81.7 degree_Celsius | degC |
| 145299 | 21FLCBA-FWB05 | 79.8 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 79.8 degree_Celsius | degC |
| 145862 | 21FLCBA-RIV02 | 74.2 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 74.2 degree_Celsius | degC |
| 145868 | 21FLCBA-RIV02 | 74.2 | NaN | ResultMeasure/MeasureUnitCode: MISSING UNITS, ... | 74.2 degree_Celsius | degC |
| 385954 | NARS_WQX-OWW04440-0401 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN | degC |
We can see where the units were missing, the results were assumed to be in degree_Celsius already
[36]:
# This is also noted in the QA_flag field
list(temperature_results.loc[df['ResultMeasure/MeasureUnitCode'].isna(), 'QA_flag'])[0]
[36]:
'ResultMeasure/MeasureUnitCode: MISSING UNITS, degC assumed'
[37]:
# Look for any without usable results
temperature_results.loc[df['Temperature'].isna()]
[37]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Temperature | Units | |
|---|---|---|---|---|---|---|
| 244719 | 11NPSWRD_WQX-GUIS_NALO | NaN | deg C | ResultMeasureValue: missing (NaN) result | NaN | degC |
| 385954 | NARS_WQX-OWW04440-0401 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN | degC |
[38]:
# Aggregate temperature data by station
visualize.station_summary(temperature_results, 'Temperature')
[38]:
| MonitoringLocationIdentifier | cnt | mean | |
|---|---|---|---|
| 0 | 11NPSWRD_WQX-GUIS_ADEM_ALPT | 30 | 24.986667 |
| 1 | 11NPSWRD_WQX-GUIS_BCCA | 1 | 36.800000 |
| 2 | 11NPSWRD_WQX-GUIS_BISA | 32 | 22.696250 |
| 3 | 11NPSWRD_WQX-GUIS_BOPI | 1 | 32.000000 |
| 4 | 11NPSWRD_WQX-GUIS_CMP_PKT01 | 20 | 25.125000 |
| ... | ... | ... | ... |
| 2544 | UWFCEDB_WQX-SRC-AI31-22 | 19 | 21.900000 |
| 2545 | UWFCEDB_WQX-SRC-AI36-22 | 26 | 21.957692 |
| 2546 | UWFCEDB_WQX-SRC-AI42-22 | 21 | 22.590476 |
| 2547 | UWFCEDB_WQX-SRC-AI44-22 | 24 | 21.095833 |
| 2548 | UWFCEDB_WQX-SRC-AK41-22 | 20 | 22.015000 |
2549 rows × 3 columns
[39]:
# Map number of usable results at each station
gdf_count = visualize.map_counts(temperature_results, stations_clipped)
gdf_count.plot(column='cnt', cmap='Blues', legend=True, scheme='quantiles', legend_kwds=legend_kwds)
[39]:
<Axes: >
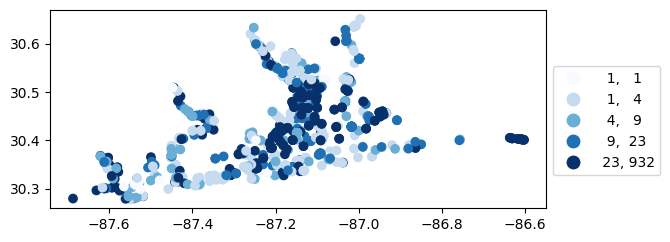
[40]:
# Map average temperature results at each station
gdf_temperature = visualize.map_measure(temperature_results, stations_clipped, 'Temperature')
gdf_temperature.plot(column='mean', cmap='OrRd', legend=True)
[40]:
<Axes: >
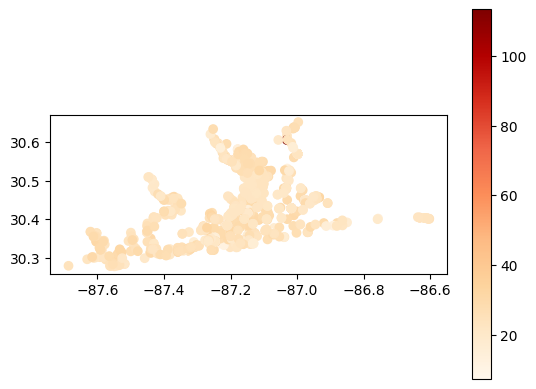
Dissolved oxygen
[41]:
# look at Dissolved oxygen (DO), but this time without intermediate fields
df = harmonize.harmonize(df, 'Dissolved oxygen (DO)')
Note: Imediately when we run a harmonization function without the intermediate fields they’re deleted.
[42]:
# Look at what was changed
cols = ['MonitoringLocationIdentifier', 'ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'DO']
do_res = df.loc[df['CharacteristicName']=='Dissolved oxygen (DO)', cols]
do_res
[42]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | DO | |
|---|---|---|---|---|---|
| 805 | FWCLOCAL-03140105-BB-02 | 10.4 | mg/l | <NA> | 10.4 milligram / liter |
| 809 | FWCLOCAL-03140105-BB-03 | 10.4 | mg/l | <NA> | 10.4 milligram / liter |
| 814 | FWCLOCAL-03140105-BB-01 | 10.2 | mg/l | <NA> | 10.2 milligram / liter |
| 817 | FWCLOCAL-03140104-BR-11 | 10.4 | mg/l | <NA> | 10.4 milligram / liter |
| 820 | FWCLOCAL-03140104-BR-06 | 11.8 | mg/l | <NA> | 11.8 milligram / liter |
| ... | ... | ... | ... | ... | ... |
| 420115 | FWCLOCAL-03140305-ER-03 | 5 | mg/l | <NA> | 5.0 milligram / liter |
| 420123 | FWCLOCAL-03140305-ER-04 | 6.4 | mg/l | <NA> | 6.4 milligram / liter |
| 420124 | FWCLOCAL-03140305-ER-05 | 5.1 | mg/l | <NA> | 5.1 milligram / liter |
| 420128 | FWCLOCAL-03140305-ER-06 | 5.1 | mg/l | <NA> | 5.1 milligram / liter |
| 420131 | FWCLOCAL-03140305-ER-02 | 7.1 | mg/l | <NA> | 7.1 milligram / liter |
74688 rows × 5 columns
[43]:
do_res.loc[do_res['ResultMeasure/MeasureUnitCode']!='mg/l']
[43]:
| MonitoringLocationIdentifier | ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | DO | |
|---|---|---|---|---|---|
| 989 | 21AWIC-942 | 7.5 | mg/L | <NA> | 7.5 milligram / liter |
| 996 | 21AWIC-942 | 7.1 | mg/L | <NA> | 7.1 milligram / liter |
| 1060 | 21AWIC-942 | 6.4 | mg/L | <NA> | 6.4 milligram / liter |
| 1065 | 21AWIC-942 | 5 | mg/L | <NA> | 5.0 milligram / liter |
| 1072 | 21AWIC-942 | 5.8 | mg/L | <NA> | 5.8 milligram / liter |
| ... | ... | ... | ... | ... | ... |
| 419519 | 11NPSWRD_WQX-GUIS_UWF_FPICKN | 8.25 | ppm | <NA> | 6.816424244849999e-07 milligram / liter |
| 420009 | 11NPSWRD_WQX-GUIS_UWF_FPICKN | 6.95 | ppm | <NA> | 5.742321030509999e-07 milligram / liter |
| 420017 | 11NPSWRD_WQX-GUIS_UWF_FPICKN | 7.2 | ppm | <NA> | 5.948879340959999e-07 milligram / liter |
| 420018 | 11NPSWRD_WQX-GUIS_UWF_FPICKN | 7.13 | ppm | <NA> | 5.891043014033999e-07 milligram / liter |
| 420022 | 11NPSWRD_WQX-GUIS_UWF_FPICKN | 6.8 | ppm | <NA> | 5.618386044239998e-07 milligram / liter |
51610 rows × 5 columns
Though there were no results in %, the conversion from percent saturation (%) to mg/l is special. This equation is being improved by integrating tempertaure and pressure instead of assuming STP (see DO_saturation())
[44]:
# Aggregate DO data by station
visualize.station_summary(do_res, 'DO')
[44]:
| MonitoringLocationIdentifier | cnt | mean | |
|---|---|---|---|
| 0 | 11NPSWRD_WQX-GUIS_ADEM_ALPT | 30 | 6.698000 |
| 1 | 11NPSWRD_WQX-GUIS_BCCA | 1 | 0.270000 |
| 2 | 11NPSWRD_WQX-GUIS_BISA | 32 | 7.194375 |
| 3 | 11NPSWRD_WQX-GUIS_BOPI | 1 | 7.540000 |
| 4 | 11NPSWRD_WQX-GUIS_FPPO | 1 | 9.950000 |
| ... | ... | ... | ... |
| 2154 | UWFCEDB_WQX-SRC-AI31-22 | 38 | 3.760918 |
| 2155 | UWFCEDB_WQX-SRC-AI36-22 | 52 | 3.514965 |
| 2156 | UWFCEDB_WQX-SRC-AI42-22 | 42 | 3.704803 |
| 2157 | UWFCEDB_WQX-SRC-AI44-22 | 48 | 3.798289 |
| 2158 | UWFCEDB_WQX-SRC-AK41-22 | 40 | 2.455314 |
2159 rows × 3 columns
[45]:
# Map number of usable results at each station
gdf_count = visualize.map_counts(do_res, stations_clipped)
gdf_count.plot(column='cnt', cmap='Blues', legend=True, scheme='quantiles', legend_kwds=legend_kwds)
[45]:
<Axes: >
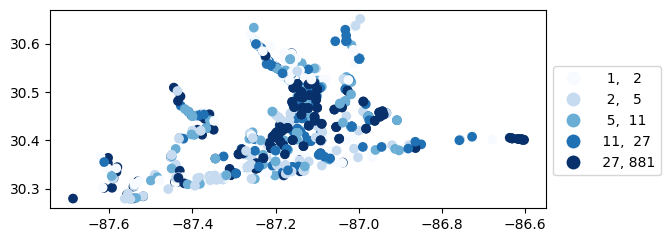
[46]:
# Map Averages at each station
gdf_avg = visualize.map_measure(do_res, stations_clipped, 'DO')
gdf_avg.plot(column='mean', cmap='OrRd', legend=True)
[46]:
<Axes: >
pH
[47]:
# pH, this time looking at a report
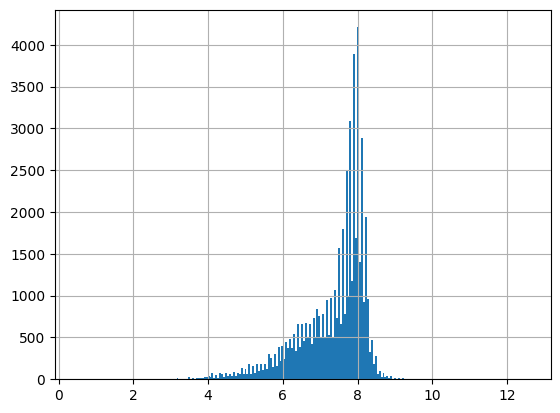
df = harmonize.harmonize(df, 'pH', report=True)
-Usable results-
count 15930.000000
mean 7.662898
std 0.714421
min 0.500000
25% 7.600000
50% 7.900000
75% 8.000000
max 10.720000
dtype: float64
Unusable results: 0
Usable results with inferred units: 14909
Results outside threshold (0.0 to 11.949425): 0
Note the warnings that occur when a unit is not recognized by the package. These occur even when report=False. Future versions could include these as defined units for pH, but here it wouldn’t alter results.
[48]:
df.loc[df['CharacteristicName']=='pH', ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'pH']]
[48]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | pH | |
|---|---|---|---|---|
| 1 | 5.6 | std units | <NA> | 5.6 dimensionless |
| 3 | 8.3 | std units | <NA> | 8.3 dimensionless |
| 4 | 4.8 | std units | <NA> | 4.8 dimensionless |
| 5 | 4.9 | std units | <NA> | 4.9 dimensionless |
| 6 | 4.9 | std units | <NA> | 4.9 dimensionless |
| ... | ... | ... | ... | ... |
| 420427 | 4.5 | std units | <NA> | 4.5 dimensionless |
| 420429 | 5.9 | std units | <NA> | 5.9 dimensionless |
| 420430 | 7.9 | std units | <NA> | 7.9 dimensionless |
| 420431 | 6.6 | std units | <NA> | 6.6 dimensionless |
| 420432 | 8.1 | std units | <NA> | 8.1 dimensionless |
15930 rows × 4 columns
‘None’ is uninterpretable and replaced with NaN, which then gets replaced with ‘dimensionless’ since pH is unitless
Salinity
[49]:
# Salinity
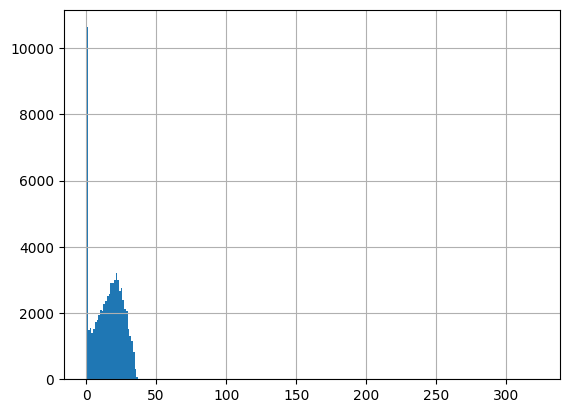
df = harmonize.harmonize(df, 'Salinity', report=True)
-Usable results-
count 78455.000000
mean 15.731318
std 145.868163
min 0.000000
25% 5.770000
50% 15.980000
75% 23.100000
max 37782.000000
dtype: float64
Unusable results: 417
Usable results with inferred units: 10
Results outside threshold (0.0 to 890.940297): 4
[50]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Salinity']
df.loc[df['CharacteristicName']=='Salinity', cols]
[50]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Salinity | |
|---|---|---|---|---|
| 1101 | .5 | ppt | <NA> | 0.5 Practical_Salinity_Units |
| 1420 | 2 | ppt | <NA> | 2.0 Practical_Salinity_Units |
| 1456 | .5 | ppt | <NA> | 0.5 Practical_Salinity_Units |
| 1462 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| 1492 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| ... | ... | ... | ... | ... |
| 420454 | 2.16 | ppth | <NA> | 2.16 Practical_Salinity_Units |
| 420455 | 2.07 | ppth | <NA> | 2.07 Practical_Salinity_Units |
| 420456 | 2.11 | ppth | <NA> | 2.11 Practical_Salinity_Units |
| 420458 | 1.89 | ppth | <NA> | 1.89 Practical_Salinity_Units |
| 420460 | 2.12 | ppth | <NA> | 2.12 Practical_Salinity_Units |
78872 rows × 4 columns
Nitrogen
[51]:
# Nitrogen
df = harmonize.harmonize(df, 'Nitrogen', report=True)
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/basis.py:343: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'as N' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
df_out.loc[mask, basis_col] = basis
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/wq_data.py:486: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '[nan nan nan nan nan nan nan nan nan nan nan nan 'as N' 'as N' 'as N'
'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N'
'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' 'as N' nan 'as N'
'as N' nan nan nan nan 'as N' nan nan 'as N' nan 'as N' nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan]' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
self.df[c_mask] = basis.basis_from_method_spec(self.df[c_mask])
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/wq_data.py:397: UserWarning: WARNING: 'cm3/g' UNDEFINED UNIT for Nitrogen
warn("WARNING: " + problem)
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/domains.py:277: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
sub_df[cols[2]] = sub_df[cols[2]].fillna(sub_df[cols[1]]) # new_fract
-Usable results-
count 109.000000
mean 26.920174
std 160.257726
min 0.000700
25% 0.410000
50% 0.629000
75% 1.120000
max 1630.000000
dtype: float64
Unusable results: 4
Usable results with inferred units: 0
Results outside threshold (0.0 to 988.466532): 1
[52]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Nitrogen']
df.loc[df['CharacteristicName']=='Nitrogen', cols]
[52]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Nitrogen | |
|---|---|---|---|---|
| 269560 | 18.99 | mg/l | <NA> | 18.99 milligram / liter |
| 269561 | 18.82 | mg/l | <NA> | 18.82 milligram / liter |
| 272015 | 16.46 | mg/l | <NA> | 16.46 milligram / liter |
| 272022 | 16.18 | mg/l | <NA> | 16.18 milligram / liter |
| 272067 | 18.72 | mg/l | <NA> | 18.72 milligram / liter |
| ... | ... | ... | ... | ... |
| 404135 | 0.3031 | mg/L | <NA> | 0.3031 milligram / liter |
| 416166 | 0.52738 | mg/L | <NA> | 0.52738 milligram / liter |
| 416278 | 0.27552 | mg/L | <NA> | 0.27552 milligram / liter |
| 417392 | 0.28634 | mg/L | <NA> | 0.28634 milligram / liter |
| 417393 | 0.5697 | mg/L | <NA> | 0.5697 milligram / liter |
113 rows × 4 columns
Conductivity
[53]:
# Conductivity
df = harmonize.harmonize(df, 'Conductivity', report=True)
-Usable results-
count 1818.000000
mean 17085.221414
std 16116.889030
min 0.040000
25% 130.000000
50% 16994.750000
75% 30306.650000
max 54886.200000
dtype: float64
Unusable results: 8
Usable results with inferred units: 0
Results outside threshold (0.0 to 113786.555592): 0
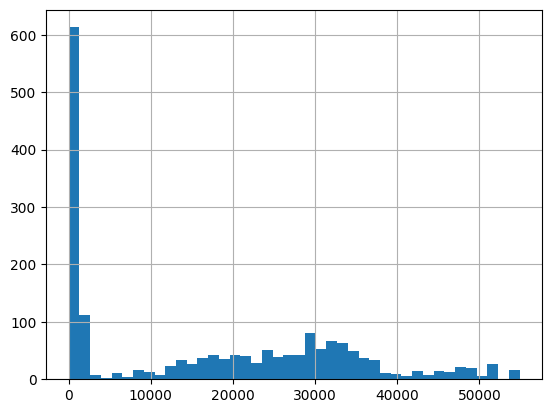
[54]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Conductivity']
df.loc[df['CharacteristicName']=='Conductivity', cols]
[54]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Conductivity | |
|---|---|---|---|---|
| 992 | 69 | umho/cm | <NA> | 69.0 microsiemens / centimeter |
| 993 | 70 | umho/cm | <NA> | 70.0 microsiemens / centimeter |
| 1056 | 70 | umho/cm | <NA> | 70.0 microsiemens / centimeter |
| 1061 | 70 | umho/cm | <NA> | 70.0 microsiemens / centimeter |
| 1074 | 90 | umho/cm | <NA> | 90.0 microsiemens / centimeter |
| ... | ... | ... | ... | ... |
| 385123 | NaN | uS/cm | ResultMeasureValue: missing (NaN) result | NaN |
| 385864 | 83.4 | uS/cm | <NA> | 83.4 microsiemens / centimeter |
| 386040 | 53.15 | uS/cm | <NA> | 53.15 microsiemens / centimeter |
| 386239 | 52 | uS/cm | <NA> | 52.0 microsiemens / centimeter |
| 386414 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
1826 rows × 4 columns
Chlorophyll a
[55]:
# Chlorophyll a
df = harmonize.harmonize(df, 'Chlorophyll a', report=True)
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/wq_data.py:397: UserWarning: WARNING: 'ug/cm2' UNDEFINED UNIT for Chlorophyll
warn("WARNING: " + problem)
-Usable results-
count 9466.000000
mean 1.145007
std 1.199148
min -0.840000
25% 0.007400
50% 0.940000
75% 1.817500
max 9.990000
dtype: float64
Unusable results: 633
Usable results with inferred units: 6175
Results outside threshold (0.0 to 8.339895): 8
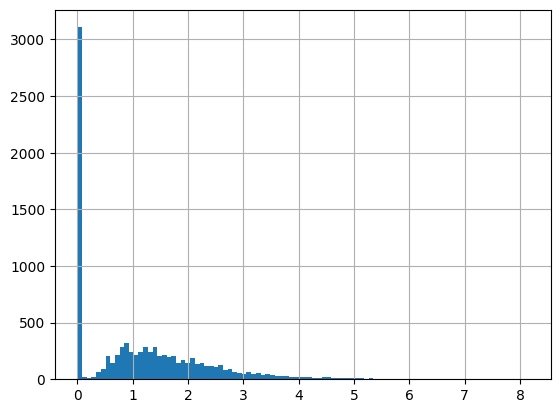
[56]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Chlorophyll']
df.loc[df['CharacteristicName']=='Chlorophyll a', cols]
[56]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Chlorophyll | |
|---|---|---|---|---|
| 28055 | 1.8 | mg/m3 | <NA> | 0.0018000000000000004 milligram / liter |
| 28069 | 8.7 | mg/m3 | <NA> | 0.008700000000000001 milligram / liter |
| 28078 | 2 | mg/m3 | <NA> | 0.0020000000000000005 milligram / liter |
| 28087 | 1.3 | mg/m3 | <NA> | 0.0013000000000000004 milligram / liter |
| 28613 | 3.7 | mg/m3 | <NA> | 0.003700000000000001 milligram / liter |
| ... | ... | ... | ... | ... |
| 419144 | 2 | ug/l | <NA> | 0.002 milligram / liter |
| 419145 | 0 | ug/l | <NA> | 0.0 milligram / liter |
| 419146 | 3 | ug/l | <NA> | 0.003 milligram / liter |
| 419147 | 2 | ug/l | <NA> | 0.002 milligram / liter |
| 419150 | 4 | ug/l | <NA> | 0.004 milligram / liter |
10099 rows × 4 columns
Organic Carbon
[57]:
# Organic carbon (%)
df = harmonize.harmonize(df, 'Organic carbon', report=True)
-Usable results-
count 5097.000000
mean 1078.102642
std 11280.440688
min 0.000000
25% 2.700000
50% 4.300000
75% 8.200000
max 410000.000000
dtype: float64
Unusable results: 165
Usable results with inferred units: 0
Results outside threshold (0.0 to 68760.746771): 22
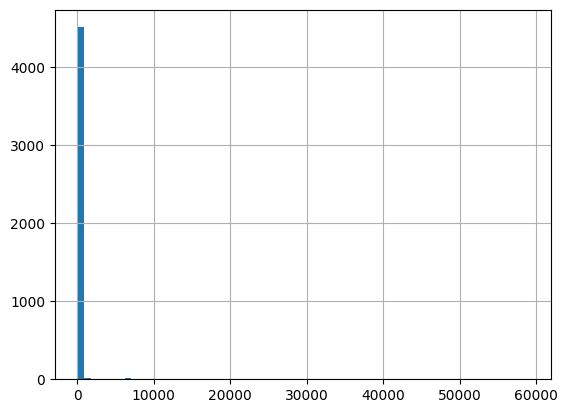
[58]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Carbon']
df.loc[df['CharacteristicName']=='Organic carbon', cols]
[58]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Carbon | |
|---|---|---|---|---|
| 111 | 570 | mg/l | <NA> | 570.0 milligram / liter |
| 112 | 560 | mg/l | <NA> | 560.0 milligram / liter |
| 113 | 6880 | mg/l | <NA> | 6880.0 milligram / liter |
| 114 | 6300 | mg/l | <NA> | 6300.0 milligram / liter |
| 128 | 7.0 | mg/l | <NA> | 7.0 milligram / liter |
| ... | ... | ... | ... | ... |
| 420205 | 658 | mg/l | <NA> | 658.0 milligram / liter |
| 420210 | 703 | mg/l | <NA> | 703.0 milligram / liter |
| 420216 | 7200 | mg/l | <NA> | 7200.0 milligram / liter |
| 420277 | 627 | mg/l | <NA> | 627.0 milligram / liter |
| 420293 | 615 | mg/l | <NA> | 615.0 milligram / liter |
5262 rows × 4 columns
Turbidity
[59]:
# Turbidity (NTU)
df = harmonize.harmonize(df, 'Turbidity', report=True)
-Usable results-
count 47797.000000
mean 30.344702
std 205.781955
min -0.840000
25% 1.600000
50% 3.000000
75% 7.570000
max 32342.452300
dtype: float64
Unusable results: 610
Usable results with inferred units: 10
Results outside threshold (0.0 to 1265.036430): 65
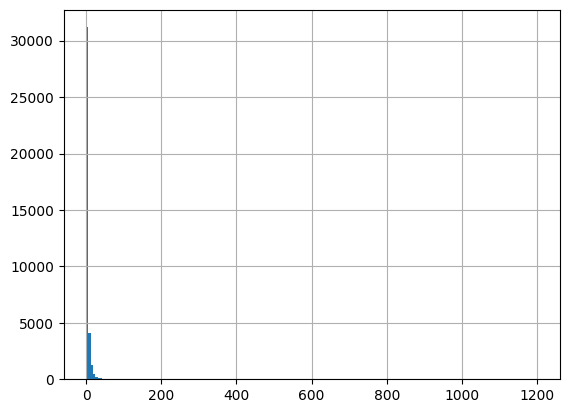
[60]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Turbidity']
df.loc[df['CharacteristicName']=='Turbidity', cols]
[60]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Turbidity | |
|---|---|---|---|---|
| 127 | 1 | JTU | <NA> | 18.9773 Nephelometric_Turbidity_Units |
| 131 | 1 | JTU | <NA> | 18.9773 Nephelometric_Turbidity_Units |
| 142 | 52 | JTU | <NA> | 989.2523 Nephelometric_Turbidity_Units |
| 147 | 13 | JTU | <NA> | 247.2773 Nephelometric_Turbidity_Units |
| 154 | 60 | JTU | <NA> | 1141.4523 Nephelometric_Turbidity_Units |
| ... | ... | ... | ... | ... |
| 419623 | 41 | JTU | <NA> | 779.9773 Nephelometric_Turbidity_Units |
| 419702 | 4 | JTU | <NA> | 76.05229999999999 Nephelometric_Turbidity_Units |
| 420369 | 0.0 | JTU | <NA> | -0.0477 Nephelometric_Turbidity_Units |
| 420388 | 50 | JTU | <NA> | 951.2022999999999 Nephelometric_Turbidity_Units |
| 420396 | 1700 | JTU | <NA> | 32342.452299999997 Nephelometric_Turbidity_Units |
48407 rows × 4 columns
Sediment
[61]:
# Sediment
df = harmonize.harmonize(df, 'Sediment', report=False)
[62]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Sediment']
df.loc[df['CharacteristicName']=='Sediment', cols]
[62]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Sediment |
|---|
Phosphorus
Note: must be merged w/ activities (package runs query by site if not already merged)
[63]:
# Phosphorus
df = harmonize.harmonize(df, 'Phosphorus')
2 Phosphorus sample fractions not in frac_dict
2 Phosphorus sample fractions not in frac_dict found in expected domains, mapped to "Other_Phosphorus"
Note: warnings for unexpected characteristic fractions. Fractions are each seperated out into their own result column.
[64]:
# All Phosphorus
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'TDP_Phosphorus']
df.loc[df['Phosphorus'].notna(), cols]
[64]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | TDP_Phosphorus | |
|---|---|---|---|---|
| 132 | 0.091 | mg/l as P | <NA> | NaN |
| 140 | 0.120 | mg/l as P | <NA> | NaN |
| 150 | 0.046 | mg/l as P | <NA> | NaN |
| 155 | 0.14 | mg/l PO4 | <NA> | NaN |
| 162 | 0.07 | mg/l PO4 | <NA> | NaN |
| ... | ... | ... | ... | ... |
| 416132 | 0.08804 | mg/L | <NA> | NaN |
| 416269 | 0.02139 | mg/L | <NA> | NaN |
| 417310 | 0.03489 | mg/L | <NA> | NaN |
| 417363 | 0.05627 | mg/L | <NA> | NaN |
| 419703 | 1.1 | mg/l PO4 | <NA> | NaN |
7799 rows × 4 columns
[65]:
# Total phosphorus
df.loc[df['TP_Phosphorus'].notna(), cols]
[65]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | TDP_Phosphorus | |
|---|---|---|---|---|
| 132 | 0.091 | mg/l as P | <NA> | NaN |
| 140 | 0.120 | mg/l as P | <NA> | NaN |
| 150 | 0.046 | mg/l as P | <NA> | NaN |
| 155 | 0.14 | mg/l PO4 | <NA> | NaN |
| 162 | 0.07 | mg/l PO4 | <NA> | NaN |
| ... | ... | ... | ... | ... |
| 416132 | 0.08804 | mg/L | <NA> | NaN |
| 416269 | 0.02139 | mg/L | <NA> | NaN |
| 417310 | 0.03489 | mg/L | <NA> | NaN |
| 417363 | 0.05627 | mg/L | <NA> | NaN |
| 419703 | 1.1 | mg/l PO4 | <NA> | NaN |
6957 rows × 4 columns
[66]:
# Total dissolved phosphorus
df.loc[df['TDP_Phosphorus'].notna(), cols]
[66]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | TDP_Phosphorus | |
|---|---|---|---|---|
| 44110 | 0.023 | mg/l as P | <NA> | 0.023 milligram / liter |
| 44118 | 0.028 | mg/l as P | <NA> | 0.028 milligram / liter |
| 45475 | 0.024 | mg/l as P | <NA> | 0.024 milligram / liter |
| 45478 | 0.033 | mg/l as P | <NA> | 0.033 milligram / liter |
| 45646 | 0.021 | mg/l as P | <NA> | 0.021 milligram / liter |
| 45651 | 0.037 | mg/l as P | <NA> | 0.037 milligram / liter |
| 45657 | 0.030 | mg/l as P | <NA> | 0.03 milligram / liter |
| 47112 | 0.025 | mg/l as P | <NA> | 0.025 milligram / liter |
| 47115 | 0.023 | mg/l as P | <NA> | 0.023 milligram / liter |
| 50770 | 0.15 | mg/l as P | <NA> | 0.15 milligram / liter |
| 50774 | 0.03 | mg/l as P | <NA> | 0.03 milligram / liter |
| 50801 | 0.05 | mg/l as P | <NA> | 0.05 milligram / liter |
| 50820 | 0.04 | mg/l as P | <NA> | 0.04 milligram / liter |
| 52117 | 0.03 | mg/l as P | <NA> | 0.03 milligram / liter |
| 52461 | 0.02 | mg/l as P | <NA> | 0.02 milligram / liter |
| 52602 | 0.02 | mg/l as P | <NA> | 0.02 milligram / liter |
| 53530 | 0.05 | mg/l as P | <NA> | 0.05 milligram / liter |
| 54503 | 0.04 | mg/l as P | <NA> | 0.04 milligram / liter |
| 54510 | 0.02 | mg/l as P | <NA> | 0.02 milligram / liter |
| 55257 | 0.08 | mg/l as P | <NA> | 0.08 milligram / liter |
| 56675 | 0.07 | mg/l as P | <NA> | 0.07 milligram / liter |
| 56788 | 0.02 | mg/l as P | <NA> | 0.02 milligram / liter |
| 57890 | 0.02 | mg/l as P | <NA> | 0.02 milligram / liter |
| 59869 | 0.03 | mg/l as P | <NA> | 0.03 milligram / liter |
| 60584 | 0.05 | mg/l as P | <NA> | 0.05 milligram / liter |
| 273063 | 0.002 | mg/L | <NA> | 0.002 milligram / liter |
| 273068 | 0.019 | mg/L | <NA> | 0.019 milligram / liter |
| 285558 | 0.003 | mg/L | <NA> | 0.003 milligram / liter |
| 285587 | 0.019 | mg/L | <NA> | 0.019 milligram / liter |
| 295257 | 0.021 | mg/L | <NA> | 0.021 milligram / liter |
| 295271 | 0.003 | mg/L | <NA> | 0.003 milligram / liter |
| 303133 | 0.002 | mg/L | <NA> | 0.002 milligram / liter |
| 303138 | 0.017 | mg/L | <NA> | 0.017 milligram / liter |
| 312426 | 0.020 | mg/L | <NA> | 0.02 milligram / liter |
| 312429 | 0.002 | mg/L | <NA> | 0.002 milligram / liter |
| 385946 | 0.00806 | mg/L | <NA> | 0.00806 milligram / liter |
| 386138 | 0.000031 | mg/L | <NA> | 3.1e-05 milligram / liter |
| 386204 | 0.002542 | mg/L | <NA> | 0.002542 milligram / liter |
| 386225 | 0.00341 | mg/L | <NA> | 0.00341 milligram / liter |
| 387954 | 0.00372 | mg/L | <NA> | 0.00372 milligram / liter |
| 388253 | 0.00961 | mg/L | <NA> | 0.00961 milligram / liter |
| 388338 | 0.00124 | mg/L | <NA> | 0.00124 milligram / liter |
| 388427 | 0.01271 | mg/L | <NA> | 0.01271 milligram / liter |
[67]:
# All other phosphorus sample fractions
df.loc[df['Other_Phosphorus'].notna(), cols]
[67]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | TDP_Phosphorus | |
|---|---|---|---|---|
| 990 | .24 | mg/L | <NA> | NaN |
| 995 | .144 | mg/L | <NA> | NaN |
| 1057 | .2 | mg/L | <NA> | NaN |
| 1064 | .25 | mg/L | <NA> | NaN |
| 1073 | .22 | mg/L | <NA> | NaN |
| ... | ... | ... | ... | ... |
| 385306 | 0.0226975 | mg/L | <NA> | NaN |
| 385316 | 0.02040375 | mg/L | <NA> | NaN |
| 385323 | 0.0169225 | mg/L | <NA> | NaN |
| 385377 | 0.02879875 | mg/L | <NA> | NaN |
| 386245 | 3 | ug/L | <NA> | NaN |
799 rows × 4 columns
Bacteria
Some equivalence assumptions are built-in where bacteria counts that are not equivalent are treated as such because there is no standard way to convert from one to another.
Fecal Coliform
[68]:
# Known unit with bad dimensionality ('Colony_Forming_Units * milliliter')
df = harmonize.harmonize(df, 'Fecal Coliform', report=True, errors='ignore')
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'MPN/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'cfu/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'CFU/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
-Usable results-
count 10035.000000
mean 45.537618
std 448.839329
min 0.000000
25% 4.000000
50% 8.000000
75% 33.000000
max 33000.000000
dtype: float64
Unusable results: 40585
Usable results with inferred units: 0
Results outside threshold (0.0 to 2738.573594): 6
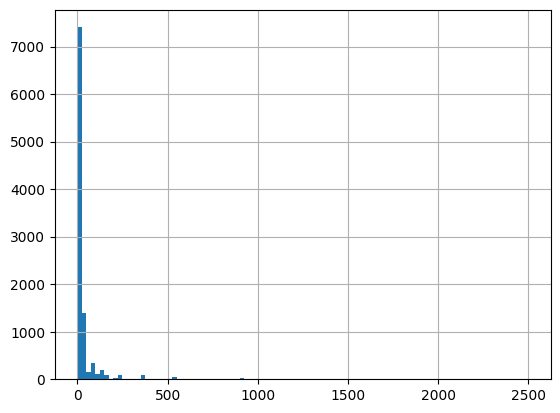
[69]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Fecal_Coliform']
df.loc[df['CharacteristicName']=='Fecal Coliform', cols]
[69]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Fecal_Coliform | |
|---|---|---|---|---|
| 558 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| 564 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| 659 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| 662 | NaN | NaN | ResultMeasureValue: missing (NaN) result; Resu... | NaN |
| 670 | 5 | MPN/100 ml | <NA> | 5.0 Colony_Forming_Units / milliliter |
| ... | ... | ... | ... | ... |
| 418631 | *Non-detect | NaN | ResultMeasureValue: "*Non-detect" result canno... | NaN |
| 418643 | 44 | cfu/100mL | <NA> | NaN |
| 418646 | NaN | cfu/100mL | ResultMeasureValue: missing (NaN) result | NaN |
| 418647 | 6 | cfu/100mL | <NA> | NaN |
| 418649 | *Non-detect | NaN | ResultMeasureValue: "*Non-detect" result canno... | NaN |
50620 rows × 4 columns
Escherichia coli
[70]:
# Known unit with bad dimensionality ('Colony_Forming_Units * milliliter')
df = harmonize.harmonize(df, 'Escherichia coli', report=True, errors='ignore')
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'MPN/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'cfu/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/harmonize_wq/convert.py:131: UserWarning: WARNING: 'CFU/100mL' converted to NaN
warn(f"WARNING: '{unit}' converted to NaN")
-Usable results-
count 22.000000
mean 501.863636
std 610.053260
min 4.000000
25% 9.500000
50% 77.500000
75% 1000.000000
max 1700.000000
dtype: float64
Unusable results: 11981
Usable results with inferred units: 0
Results outside threshold (0.0 to 4162.183199): 0
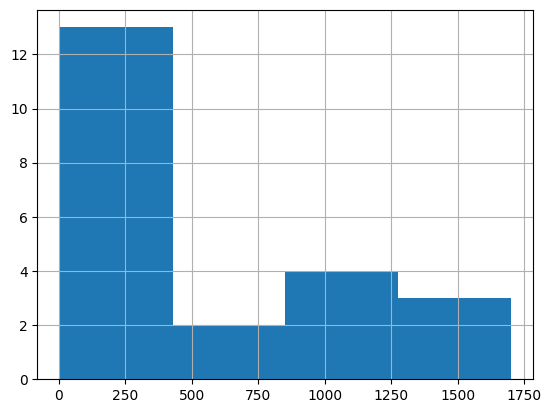
[71]:
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'E_coli']
df.loc[df['CharacteristicName']=='Escherichia coli', cols]
[71]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | E_coli | |
|---|---|---|---|---|
| 61483 | 0 | cfu/100mL | <NA> | NaN |
| 61989 | 0 | cfu/100mL | <NA> | NaN |
| 62022 | 100 | cfu/100mL | <NA> | NaN |
| 62029 | 0 | cfu/100mL | <NA> | NaN |
| 62030 | 0 | cfu/100mL | <NA> | NaN |
| ... | ... | ... | ... | ... |
| 384777 | 1200 | MPN/100mL | <NA> | NaN |
| 384787 | 130 | MPN/100mL | <NA> | NaN |
| 384799 | 2400 | MPN/100mL | <NA> | NaN |
| 384805 | 170 | MPN/100mL | <NA> | NaN |
| 384822 | 91 | MPN/100mL | <NA> | NaN |
12003 rows × 4 columns
Combining Salinity and Conductivity
Convert module has various functions to convert from one unit or characteristic to another. Some of these are used within a single characteristic during harmonization (e.g. DO saturation to concentration) while others are intended to model one characteristic as an indicator of another (e.g. estimate salinity from conductivity).
Note: this should only be done after both characteristic fields have been harmonized. Results before and after should be inspected, thresholds for outliers applied, and consider adding a QA_flag for modeled data.
Explore Salinity results:
[72]:
from harmonize_wq import convert
[73]:
# Salinity summary statistics
lst = [x.magnitude for x in list(df['Salinity'].dropna())]
q_sum = sum(lst)
print('Range: {} to {}'.format(min(lst), max(lst)))
print('Results: {} \nMean: {} PSU'.format(len(lst), q_sum/len(lst)))
Range: 0.0 to 37782.0
Results: 78455
Mean: 15.731317924926191 PSU
[74]:
# Identify extreme outliers
[x for x in lst if x >3200]
[74]:
[37782.0, 15030.0]
Other fields like units and QA_flag may help understand what caused high values and what results might need to be dropped from consideration
[75]:
# Columns to focus on
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Salinity']
[76]:
# Look at important fields for max 5 values
salinity_series = df['Salinity'][df['Salinity'].notna()]
salinity_series.sort_values(ascending=False, inplace=True)
df[cols][df['Salinity'].isin(salinity_series[0:5])]
[76]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Salinity | |
|---|---|---|---|---|
| 216565 | 2190 | ppt | <NA> | 2190.0 Practical_Salinity_Units |
| 233941 | 37782 | ppth | <NA> | 37782.0 Practical_Salinity_Units |
| 245609 | 2150 | ppth | <NA> | 2150.0 Practical_Salinity_Units |
| 276550 | 322 | ppth | <NA> | 322.0 Practical_Salinity_Units |
| 277791 | 15030 | ppt | <NA> | 15030.0 Practical_Salinity_Units |
Detection limits may help understand what caused low values and what results might need to be dropped or updated
[77]:
from harmonize_wq import wrangle
[78]:
df = wrangle.add_detection(df, 'Salinity')
cols+=['ResultDetectionConditionText',
'DetectionQuantitationLimitTypeName',
'DetectionQuantitationLimitMeasure/MeasureValue',
'DetectionQuantitationLimitMeasure/MeasureUnitCode']
[79]:
# Look at important fields for min 5 values (often multiple 0.0)
df[cols][df['Salinity'].isin(salinity_series[-5:])]
[79]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Salinity | ResultDetectionConditionText | DetectionQuantitationLimitTypeName | DetectionQuantitationLimitMeasure/MeasureValue | DetectionQuantitationLimitMeasure/MeasureUnitCode | |
|---|---|---|---|---|---|---|---|---|
| 30733 | 0 | ppth | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 55996 | 0 | ppt | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 56276 | 0 | ppt | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 57393 | 0 | ppt | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 57989 | 0 | ppt | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 375865 | 0 | PSS | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 383811 | 0 | ppt | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 384275 | 0 | ppth | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 419295 | 0 | ppth | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
| 419327 | 0 | ppth | <NA> | 0.0 Practical_Salinity_Units | NaN | NaN | NaN | NaN |
3051 rows × 8 columns
Explore Conductivity results:
[80]:
# Create series and inspect Conductivity values
cond_series = df['Conductivity'].dropna()
cond_series
[80]:
992 69.0 microsiemens / centimeter
993 70.0 microsiemens / centimeter
1056 70.0 microsiemens / centimeter
1061 70.0 microsiemens / centimeter
1074 90.0 microsiemens / centimeter
...
277864 29.0 microsiemens / centimeter
384830 169.0 microsiemens / centimeter
385864 83.4 microsiemens / centimeter
386040 53.15 microsiemens / centimeter
386239 52.0 microsiemens / centimeter
Name: Conductivity, Length: 1818, dtype: object
Conductivity thresholds from Freshwater Explorer: 10 > x < 5000 us/cm, use a higher threshold for coastal waters
[81]:
# Sort and check other relevant columns before converting (e.g. Salinity)
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Salinity', 'Conductivity']
df.sort_values(by=['Conductivity'], ascending=False, inplace=True)
df.loc[df['Conductivity'].notna(), cols]
[81]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Salinity | Conductivity | |
|---|---|---|---|---|---|
| 209824 | 54886.2 | umho/cm | <NA> | NaN | 54886.2 microsiemens / centimeter |
| 209837 | 54871.3 | umho/cm | <NA> | NaN | 54871.3 microsiemens / centimeter |
| 209825 | 54860.6 | umho/cm | <NA> | NaN | 54860.6 microsiemens / centimeter |
| 209839 | 54859.3 | umho/cm | <NA> | NaN | 54859.3 microsiemens / centimeter |
| 209831 | 54850.8 | umho/cm | <NA> | NaN | 54850.8 microsiemens / centimeter |
| ... | ... | ... | ... | ... | ... |
| 193501 | 6.8 | umho/cm | <NA> | NaN | 6.8 microsiemens / centimeter |
| 244816 | 2 | umho/cm | <NA> | NaN | 2.0 microsiemens / centimeter |
| 222631 | 2 | umho/cm | <NA> | NaN | 2.0 microsiemens / centimeter |
| 254066 | 1 | umho/cm | <NA> | NaN | 1.0 microsiemens / centimeter |
| 217914 | .04 | umho/cm | <NA> | NaN | 0.04 microsiemens / centimeter |
1818 rows × 5 columns
[82]:
# Check other relevant columns before converting (e.g. Salinity)
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'QA_flag', 'Salinity', 'Conductivity']
df.loc[df['Conductivity'].notna(), cols]
[82]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | QA_flag | Salinity | Conductivity | |
|---|---|---|---|---|---|
| 209824 | 54886.2 | umho/cm | <NA> | NaN | 54886.2 microsiemens / centimeter |
| 209837 | 54871.3 | umho/cm | <NA> | NaN | 54871.3 microsiemens / centimeter |
| 209825 | 54860.6 | umho/cm | <NA> | NaN | 54860.6 microsiemens / centimeter |
| 209839 | 54859.3 | umho/cm | <NA> | NaN | 54859.3 microsiemens / centimeter |
| 209831 | 54850.8 | umho/cm | <NA> | NaN | 54850.8 microsiemens / centimeter |
| ... | ... | ... | ... | ... | ... |
| 193501 | 6.8 | umho/cm | <NA> | NaN | 6.8 microsiemens / centimeter |
| 244816 | 2 | umho/cm | <NA> | NaN | 2.0 microsiemens / centimeter |
| 222631 | 2 | umho/cm | <NA> | NaN | 2.0 microsiemens / centimeter |
| 254066 | 1 | umho/cm | <NA> | NaN | 1.0 microsiemens / centimeter |
| 217914 | .04 | umho/cm | <NA> | NaN | 0.04 microsiemens / centimeter |
1818 rows × 5 columns
[83]:
# Convert values to PSU and write to Salinity
cond_series = cond_series.apply(str) # Convert to string to convert to dimensionless (PSU)
df.loc[df['Conductivity'].notna(), 'Salinity'] = cond_series.apply(convert.conductivity_to_PSU)
df.loc[df['Conductivity'].notna(), 'Salinity']
[83]:
209824 36.356 dimensionless
209837 36.345 dimensionless
209825 36.338 dimensionless
209839 36.336 dimensionless
209831 36.33 dimensionless
...
193501 0.013 dimensionless
244816 0.012 dimensionless
222631 0.012 dimensionless
254066 0.012 dimensionless
217914 0.012 dimensionless
Name: Salinity, Length: 1818, dtype: object
Datetime
datetime() formats time using dataretrieval and ActivityStart
[84]:
# First inspect the existing unformated fields
cols = ['ActivityStartDate', 'ActivityStartTime/Time', 'ActivityStartTime/TimeZoneCode']
df[cols]
[84]:
| ActivityStartDate | ActivityStartTime/Time | ActivityStartTime/TimeZoneCode | |
|---|---|---|---|
| 209824 | 2007-08-09 | 12:15:00 | CST |
| 209837 | 2007-08-09 | 12:15:00 | CST |
| 209825 | 2007-08-09 | 12:15:00 | CST |
| 209839 | 2007-08-09 | 12:15:00 | CST |
| 209831 | 2007-08-09 | 12:15:00 | CST |
| ... | ... | ... | ... |
| 420456 | 1968-08-03 | NaN | NaN |
| 420457 | 1968-08-03 | NaN | NaN |
| 420458 | 1968-08-03 | NaN | NaN |
| 420459 | 1968-08-03 | NaN | NaN |
| 420460 | 1968-08-03 | NaN | NaN |
420461 rows × 3 columns
[85]:
# 'ActivityStartDate' presserves date where 'Activity_datetime' is NAT due to no time zone
df = clean.datetime(df)
df[['ActivityStartDate', 'Activity_datetime']]
[85]:
| ActivityStartDate | Activity_datetime | |
|---|---|---|
| 209824 | 2007-08-09 | 2007-08-09 18:15:00+00:00 |
| 209837 | 2007-08-09 | 2007-08-09 18:15:00+00:00 |
| 209825 | 2007-08-09 | 2007-08-09 18:15:00+00:00 |
| 209839 | 2007-08-09 | 2007-08-09 18:15:00+00:00 |
| 209831 | 2007-08-09 | 2007-08-09 18:15:00+00:00 |
| ... | ... | ... |
| 420456 | 1968-08-03 | NaT |
| 420457 | 1968-08-03 | NaT |
| 420458 | 1968-08-03 | NaT |
| 420459 | 1968-08-03 | NaT |
| 420460 | 1968-08-03 | NaT |
420461 rows × 2 columns
Activity_datetime combines all three time component columns into UTC. If time is missing this is NaT so a ActivityStartDate column is used to preserve date only.
Depth
Note: Data are often lacking sample depth metadata
[86]:
# Depth of sample (default units='meter')
df = clean.harmonize_depth(df)
#df.loc[df['ResultDepthHeightMeasure/MeasureValue'].dropna(), "Depth"]
df['ResultDepthHeightMeasure/MeasureValue'].dropna()
[86]:
193039 1.0
193851 16.0
193852 16.0
217684 35.0
270719 7.0
...
385123 0.1
385124 1.3
385125 0.5
385126 2.0
385127 2.2
Name: ResultDepthHeightMeasure/MeasureValue, Length: 125, dtype: float64
Characteristic to Column (long to wide format)
[87]:
# Split single QA column into multiple by characteristic (rename the result to preserve these QA_flags)
df2 = wrangle.split_col(df)
df2
[87]:
| OrganizationIdentifier | OrganizationFormalName | ActivityIdentifier | ActivityStartDate | ActivityStartTime/Time | ActivityStartTime/TimeZoneCode | MonitoringLocationIdentifier | ResultIdentifier | DataLoggerLine | ResultDetectionConditionText | ... | QA_Secchi | QA_Turbidity | QA_Chlorophyll | QA_DO | QA_E_coli | QA_Nitrogen | QA_Salinity | QA_pH | QA_Temperature | QA_Carbon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 209824 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230231_173 | 2007-08-09 | 12:15:00 | CST | 21AWIC-1122 | STORET-170383613 | 230231.0 | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209837 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230230_173 | 2007-08-09 | 12:15:00 | CST | 21AWIC-1122 | STORET-170383607 | 230230.0 | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209825 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230228_173 | 2007-08-09 | 12:15:00 | CST | 21AWIC-1122 | STORET-170383595 | 230228.0 | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209839 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230229_173 | 2007-08-09 | 12:15:00 | CST | 21AWIC-1122 | STORET-170383601 | 230229.0 | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209831 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230227_173 | 2007-08-09 | 12:15:00 | CST | 21AWIC-1122 | STORET-170383589 | 230227.0 | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 420456 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_1_19680803_1415864 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_1 | STORET-742739949 | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 420457 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_S_19680803_1415863 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_S | STORET-742740047 | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 420458 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415874 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740009 | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 420459 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415872 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740002 | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 420460 | 11NPSWRD_WQX | National Park Service Water Resources Division | 11NPSWRD_WQX-GUIS_FTPICKNS_2_19680803_1415873 | 1968-08-03 | NaN | NaN | 11NPSWRD_WQX-GUIS_FTPICKNS_2 | STORET-742740006 | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
365642 rows × 120 columns
[88]:
# This expands the single col (QA_flag) out to a number of new columns based on the unique characteristicNames and speciation
print('{} new columns'.format(len(df2.columns) - len(df.columns)))
14 new columns
[89]:
# Note: there are fewer rows because NAN results are also dropped in this step
print('{} fewer rows'.format(len(df)-len(df2)))
54819 fewer rows
[90]:
#Examine Carbon flags from earlier in notebook (note these are empty now because NAN is dropped)
cols = ['ResultMeasureValue', 'ResultMeasure/MeasureUnitCode', 'Carbon', 'QA_Carbon']
df2.loc[df2['QA_Carbon'].notna(), cols]
[90]:
| ResultMeasureValue | ResultMeasure/MeasureUnitCode | Carbon | QA_Carbon |
|---|
Next the table is divided into the columns of interest (main_df) and characteristic specific metadata (chars_df)
[91]:
# split table into main and characteristics tables
main_df, chars_df = wrangle.split_table(df2)
[92]:
# Columns still in main table
main_df.columns
[92]:
Index(['OrganizationIdentifier', 'OrganizationFormalName',
'ActivityIdentifier', 'MonitoringLocationIdentifier', 'ProviderName',
'ActivityStartDateTime', 'AnalysisStartDateTime', 'AnalysisEndDateTime',
'Secchi', 'Temperature', 'DO', 'pH', 'Salinity', 'Nitrogen',
'Speciation', 'TOTAL NITROGEN_ MIXED FORMS', 'Conductivity',
'Chlorophyll', 'Carbon', 'Turbidity', 'Sediment', 'Phosphorus',
'TP_Phosphorus', 'TDP_Phosphorus', 'Other_Phosphorus', 'Fecal_Coliform',
'E_coli', 'DetectionQuantitationLimitTypeName',
'DetectionQuantitationLimitMeasure/MeasureValue',
'DetectionQuantitationLimitMeasure/MeasureUnitCode',
'Activity_datetime', 'Depth', 'QA_Fecal_Coliform', 'QA_Conductivity',
'QA_TP_Phosphorus', 'QA_TDP_Phosphorus', 'QA_Other_Phosphorus',
'QA_Secchi', 'QA_Turbidity', 'QA_Chlorophyll', 'QA_DO', 'QA_E_coli',
'QA_Nitrogen', 'QA_Salinity', 'QA_pH', 'QA_Temperature', 'QA_Carbon'],
dtype='object')
[93]:
# look at main table results (first 5)
main_df.head()
[93]:
| OrganizationIdentifier | OrganizationFormalName | ActivityIdentifier | MonitoringLocationIdentifier | ProviderName | ActivityStartDateTime | AnalysisStartDateTime | AnalysisEndDateTime | Secchi | Temperature | ... | QA_Secchi | QA_Turbidity | QA_Chlorophyll | QA_DO | QA_E_coli | QA_Nitrogen | QA_Salinity | QA_pH | QA_Temperature | QA_Carbon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 209824 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230231_173 | 21AWIC-1122 | STORET | 2007-08-09 18:15:00+00:00 | NaT | NaT | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209837 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230230_173 | 21AWIC-1122 | STORET | 2007-08-09 18:15:00+00:00 | NaT | NaT | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209825 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230228_173 | 21AWIC-1122 | STORET | 2007-08-09 18:15:00+00:00 | NaT | NaT | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209839 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230229_173 | 21AWIC-1122 | STORET | 2007-08-09 18:15:00+00:00 | NaT | NaT | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 209831 | 21AWIC | ALABAMA DEPT. OF ENVIRONMENTAL MANAGEMENT - WA... | 21AWIC-51908_230227_173 | 21AWIC-1122 | STORET | 2007-08-09 18:15:00+00:00 | NaT | NaT | NaN | NaN | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
5 rows × 47 columns
[94]:
# Empty columns that could be dropped (Mostly QA columns)
cols = list(main_df.columns)
x = main_df.dropna(axis=1, how='all')
[col for col in cols if col not in x.columns]
[94]:
['AnalysisStartDateTime',
'AnalysisEndDateTime',
'Sediment',
'QA_Fecal_Coliform',
'QA_Conductivity',
'QA_TP_Phosphorus',
'QA_TDP_Phosphorus',
'QA_Other_Phosphorus',
'QA_Secchi',
'QA_E_coli',
'QA_Carbon']
[95]:
# Map average results at each station
gdf_avg = visualize.map_measure(main_df, stations_clipped, 'Temperature')
gdf_avg.plot(column='mean', cmap='OrRd', legend=True)
[95]:
<Axes: >