Batch Execution of Analyses¶
Table of Contents¶
Batch execution¶
If you have several dose-response datasets, you can run them as a batch.
For example, consider a CSV with one row per dataset, using commas to separate columns, and semicolons to separate dose groups within a column:
ID,Dose,Incidence,N
1,0;0.5;1,0;3;5,5;5;5
2,0;0.33;0.67;1,0;0;4;5,5;5;5;5
To run in pybmds, you’ll first need to load the dataset into a data frame using the pandas library:
import pandas as pd
df = pd.read_csv("data/batch.csv")
df.head()
| ID | Dose | Incidence | N | |
|---|---|---|---|---|
| 0 | 1 | 0;0.5;1 | 0;3;5 | 5;5;5 |
| 1 | 2 | 0;0.33;0.67;1 | 0;0;4;5 | 5;5;5;5 |
To model, convert the data in a data frame into a list of pybmds.DichotomousDataset objects:
import pybmds
def create_dataset(row):
return pybmds.DichotomousDataset(
id=row.ID,
doses=list(map(float, row.Dose.split(";"))),
ns=list(map(int, row.N.split(";"))),
incidences=list(map(int, row.Incidence.split(";"))),
)
dichotomous_datasets = df.apply(create_dataset, axis=1).tolist()
# plot the first dataset as an example
fig = dichotomous_datasets[0].plot()
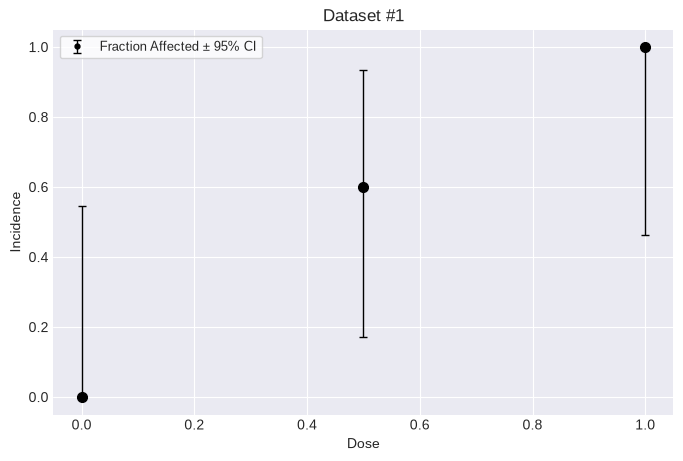
Single model, multiple datasets¶
With datasets loaded, we can run a single model for each dataset:
from pybmds.models import dichotomous
dichotomous_results = []
for dataset in dichotomous_datasets:
model = dichotomous.Multistage(dataset=dataset, settings={"degree": 2})
result = model.execute()
dichotomous_results.append(model)
And then we could export a simple list of results:
outputs = [
[
model.dataset.metadata.id,
model.name(),
model.results.bmd,
model.results.bmdl,
model.results.bmdu,
]
for model in dichotomous_results
]
output_df = pd.DataFrame(data=outputs, columns="Dataset-ID Name BMD BMDL BMDU".split())
output_df.head()
| Dataset-ID | Name | BMD | BMDL | BMDU | |
|---|---|---|---|---|---|
| 0 | 1 | Multistage 2 | 0.159996 | 0.023905 | 0.240851 |
| 1 | 2 | Multistage 2 | 0.192018 | 0.074073 | 0.271778 |
Session batch execution¶
Alternatively, you could run a session that executes a suite of models and returns the best-fitting result:
# function takes a dataset as input and returns an execution response
def runner(ds):
sess = pybmds.Session(dataset=ds)
sess.add_model(pybmds.Models.Logistic, settings={"bmr": 0.2})
sess.add_model(pybmds.Models.Probit, settings={"bmr": 0.2})
sess.execute_and_recommend()
return pybmds.BatchResponse(success=True, content=[sess.to_dict()])
# execute all datasets and sessions on a single processor
batch = pybmds.BatchSession().execute(dichotomous_datasets, runner, nprocs=1)
Save Excel and Word reports:
batch.to_excel("output/batch.xlsx")
batch.to_docx().save("output/batch.docx")
You could even run two sessions for each dataset by, for example, running two different BMRs. The only change to the code above is modifying the runner function:
def runner2(ds):
sess1 = pybmds.Session(dataset=ds)
sess1.add_model(pybmds.Models.Logistic, settings={"bmr": 0.1})
sess1.add_model(pybmds.Models.Probit, settings={"bmr": 0.1})
sess1.execute_and_recommend()
sess2 = pybmds.Session(dataset=ds)
sess2.add_model(pybmds.Models.Logistic, settings={"bmr": 0.2})
sess2.add_model(pybmds.Models.Probit, settings={"bmr": 0.2})
sess2.execute_and_recommend()
return pybmds.BatchResponse(success=True, content=[sess1.to_dict(), sess2.to_dict()])
batch = pybmds.BatchSession().execute(dichotomous_datasets, runner2, nprocs=1)
Batch running trend-tests¶
If you have several dose-response datasets, you can run them in a batch. For example, consider a CSV formated as above with one row per dataset, using commas to separate columns, and semicolons to separate dose groups within a column:
ID,Dose,Incidence,N
1,0;25;75;125;200,0;1;7;15;19,20;20;20;20;20
2,0;25;75;125;200,0;1;2;1;2,20;20;20;20;20
3,0;25;75;125;200,0;1;3;6;8,20;20;20;20;20
To run the Cochran-Armitage tests on all the datasets in the CSV file, first load the dataset into a data frame using pandas:
import pybmds
import pandas as pd
df = pd.read_csv('data/batch_catt.csv')
df.head()
| ID | dose | incidence | n | |
|---|---|---|---|---|
| 0 | 1 | 0;25;75;125; 200 | 0;1;7;15;19 | 20;20;20;20;20 |
| 1 | 2 | 0;25;75;125; 200 | 0;1;2;1;2 | 20;20;20;20;20 |
| 2 | 3 | 0;25;75;125; 200 | 0;1;3;6;8 | 20;20;20;20;20 |
Next, loop through each row in the data frame, and run the Cochran-Armitage test on each dataset:
for i, row in df.iterrows():
dose = [float(x) for x in row['dose'].split(';')]
ns = [int(x) for x in row['n'].split(';')]
incidences = [int(x) for x in row['incidence'].split(';')]
dataset = pybmds.DichotomousDataset(doses=dose, ns=ns, incidences=incidences)
trend_result = dataset.trend()
print(f"Dataset {i+1} Results:")
print(trend_result.tbl())
Dataset 1 Results:
╒══════════════════════╤══════════════╕
│ Statistic │ -7.49587 │
│ P-Value (Asymptotic) │ 3.29291e-14 │
│ P-Value (Exact) │ 1.20646e-16 │
╘══════════════════════╧══════════════╛
Dataset 2 Results:
╒══════════════════════╤═══════════╕
│ Statistic │ -1.11483 │
│ P-Value (Asymptotic) │ 0.132461 │
│ P-Value (Exact) │ 0.1524 │
╘══════════════════════╧═══════════╛
Dataset 3 Results:
╒══════════════════════╤══════════════╕
│ Statistic │ -3.88094 │
│ P-Value (Asymptotic) │ 5.20266e-05 │
│ P-Value (Exact) │ 7.35424e-05 │
╘══════════════════════╧══════════════╛
Note that, conceptually, a batch approach can be used to run the Jonckheere-Terpstra trend test as well. However, given that the exact Jonckheere-Terpstra trend test uses a permutation approach to calculate the p-value, the computational burden can be large and memory issues may arise if a large number of datasets are run in a batch fashion. Caution is advised when running the exact Jonckheere-Terpstra trend test in a batch fashion. If batch analysis is required, it may be adventageous to use the approximate trend test instead.