TADA Cybertown Workshop June 2025
TADA Team
2026-07-15
Source:vignettes/TADACybertown2025.Rmd
TADACybertown2025.RmdAccessing vignette
A vignette is a long-form guide to a package often written as a R Markdown document, such as this one. It provides detailed explanations of functions and showcases an example workflow. This vignette can be created as an html document or other format using the knit option on the top of the RStudio toolbar. Users can also access this vignette on the EPATADA GitHub page found (here).
Load libraries
First, please install the EPATADA R package by following the instructions here. Next, load the EPATADA R Package.
Record start time
start.time <- Sys.time()Retrieve
Query the WQP using TADA_DataRetrieval. TADA_AutoClean is a powerful function that runs as part of TADA_DataRetrieval when applyautoclean = TRUE. It performs a variety of tasks, for example:
creating new “TADA” prefixed columns and and capitalizing their contents to reduce case sensitivity issues,
converts special characters in value columns,
converts latitude and longitude values to numeric,
replaces “meters” with “m”,
replaces deprecated characteristic names with current WQX names,
harmonizes result and detection limit units,
converts depths to meters, and
creates the column TADA.ComparableDataIdentifier by concatenating characteristic name, result sample fraction, method speciation, and result measure unit.
In this example, we will first leverage EPA’s How’s My Waterway (HMW) application to discover an ATTAINS Assessment Unit of interest (example waterbody report). Then, we will use the Assessment Unit ID to query ATTAINS geospatial services for the associated shapefile (polygon area of the Assessment Unit). Now we can use this shapefile (only works for polygons for now) as our input for the new aoi_sf query option included in TADA_DataRetrieval. This allows us to download WQP data within the Assessment Unit (our area of interest/AOI).
query.params <- list(
where = "assessmentunitidentifier IN ('CT6400-00-1-L5_01')",
outFields = "*",
f = "geojson"
)
url <- "https://gispub.epa.gov/arcgis/rest/services/OW/ATTAINS_Assessment/MapServer/2/query?"
poly.response <- httr::GET(url, query = query.params)
poly.geojson <- httr::content(poly.response, as = "text", encoding = "UTF-8")
poly.sf <- sf::st_read(poly.geojson, quiet = TRUE)
WQP_raw <- TADA_DataRetrieval(
startDate = "null",
endDate = "null",
aoi_sf = poly.sf,
countrycode = "null",
countycode = "null",
huc = "null",
siteid = "null",
siteType = "null",
tribal_area_type = "null",
tribe_name_parcel = "null",
characteristicName = "null",
characteristicType = "null",
sampleMedia = "null",
statecode = "null",
organization = "null",
project = "null",
providers = "null",
bBox = "null",
maxrecs = 350000,
ask = FALSE,
applyautoclean = TRUE
)Remove intermediate variables in R by using ‘rm()’.
rm(poly.response, poly.sf, query.params, poly.geojson, url)Flag, clean, and visualize
Now, let’s use EPATADA functions to review, visualize, and whittle the returned WQP data down to include only results that are applicable to our water quality analysis and area of interest.
TADA is primarily designed to accommodate water data from the WQP. Let’s see what activity media types are represented in the data set. Are there any media type that are not water in our data frame?
# Create table with count for each ActivityMediaName
TADA_FieldValuesTable(
WQP_raw,
field = "ActivityMediaName",
characteristicName = "null"
)Create an overview map.
TADA_OverviewMap(WQP_raw)Let’s take a quick look at all unique values in the MonitoringLocationIdentifier column and see how how many results are associated with each.
# use TADA_FieldValuesTable to create a table of the number of results per MonitoringLocationIdentifier
sites <- TADA_FieldValuesTable(
WQP_raw,
field = "MonitoringLocationIdentifier",
characteristicName = "null"
)
DT::datatable(sites, fillContainer = TRUE)Are there sites located within 100 meters of each other?
WQP_clean <- TADA_FindNearbySites(
WQP_raw,
dist_buffer = 100,
nhd_res = "Hi",
org_hierarchy = "none",
meta_select = "random",
by_AU = FALSE,
catchment = FALSE
)
TADA_NearbySitesMap(WQP_clean)Now let’s review all unique values in the TADA.ComparableDataIdentifier column and see how how many results are associated with each. TADA.ComparableDataIdentifier concatenates TADA.CharacteristicName, TADA.ResultSampleFractionText, TADA.MethodSpeciationName, and TADA.ResultMeasure.MeasureUnitCode.
# use TADA_FieldValuesTable to create a table of the number of results per TADA.ComparableDataIdentifier
chars <- TADA_FieldValuesTable(
WQP_clean,
field = "TADA.ComparableDataIdentifier",
characteristicName = "null"
)
DT::datatable(chars, fillContainer = TRUE)Remove intermediate variables in R by using ‘rm()’.
rm(chars, sites, WQP_flag_review, WQP_flag)Next, let’s check if the dataset contains potential duplicate results from within a single organization or from within multiple organizations (such as when two or more organizations monitor the same location and may submit duplicate results).
If you would like to prioritize results from one organization over
another, this can be done using the org_hierarchy argument in
TADA_FindPotentialDuplicatesMultipleOrgs.
# find duplicates from single org
WQP_flag <- TADA_FindPotentialDuplicatesSingleOrg(WQP_clean)
# Review organizations. You can select one to prioritize in TADA_FindPotentialDuplicatesMultipleOrgs
unique(WQP_flag$OrganizationIdentifier)
unique(WQP_flag$OrganizationFormalName)
# find duplicates across multiple orgs
WQP_flag <- TADA_FindPotentialDuplicatesMultipleOrgs(
WQP_flag,
org_hierarchy = c("CT_DEP01", "USGS-CT", "CTVOLMON", "NALMS")
)Let’s review the duplicates:
# Review duplicate groupings
WQP_flag_review <- WQP_flag |>
dplyr::select(
OrganizationIdentifier,
MonitoringLocationIdentifier,
ActivityTypeCode,
ActivityStartDate,
ActivityStartTime.Time,
TADA.ComparableDataIdentifier,
SubjectTaxonomicName,
TADA.ResultMeasureValue,
TADA.ResultDepthHeightMeasure.MeasureValue,
TADA.ResultDepthHeightMeasure.MeasureUnitCode,
TADA.MultipleOrgDupGroupID,
TADA.MultipleOrgDup.Flag
) |>
dplyr::arrange(TADA.MultipleOrgDupGroupID)We will select to keep only unique samples from
TADA_FindPotentialDuplicatesSingleOrg by filtering for
TADA.SingleOrgDup.Flag equals “Unique”.
There are no multiple org duplicates from
TADA_FindPotentialDuplicatesMultipleOrgs in this example,
but if there were, duplicates can by removed by filtering for
TADA.ResultSelectedMultipleOrgs equals “Y”.
WQP_clean <- TADA_FindPotentialDuplicatesMultipleOrgs(WQP_flag, clean = T) |>
TADA_FindPotentialDuplicatesSingleOrg(WQP_flag, clean = T)Remove intermediate variables in R by using ‘rm()’. In the remainder of this workshop, we will work with the clean data set.
rm(WQP_flag, WQP_flag_review)Censored data are measurements for which the true value is not known,
but we can estimate the value based on known lower or upper detection
conditions and limit types. TADA fills missing
TADA.ResultMeasureValue and
TADA.ResultMeasure.MeasureUnitCode values with values and units
from TADA.DetectionQuantitationLimitMeasure.MeasureValue and
TADA.DetectionQuantitationLimitMeasure.MeasureUnitCode,
respectively, using the TADA_AutoClean function.
The TADA package currently has functions that summarize censored data
incidence in the dataset and perform simple substitutions of censored
data values, including x times the detection limit and random selection
of a value between 0 and the detection limit. The user may specify the
methods used for non-detects and over-detects separately in the input to
the TADA_SimpleCensoredMethods function. The next step we
take in this example is to perform simple conversions to the censored
data in the dataset: we keep over-detects as is (no conversion made) and
convert non-detect values to 0.5 times the detection limit (half the
detection limit).
WQP_clean <- TADA_SimpleCensoredMethods(
WQP_clean,
nd_method = "multiplier",
nd_multiplier = 0.5,
od_method = "as-is",
od_multiplier = "null"
)TADA_FindQCActivities removes results with QA/QC
ActivityTypeCode’s.
WQP_clean <- TADA_FindQCActivities(WQP_clean, clean = TRUE)TADA_ConvertSpecialChars removes rows where the result
value is not numeric to prepare a dataframe for quantitative analyses.
Specifically, this function removes rows with “Text” and “NA - Not
Available” in the TADA.ResultMeasureValueDataTypes.Flag column, or NA in
the TADA.ResultMeasureValue column. In addition, this function removes
results with QA/QC ActivityTypeCode’s. This function also removes any
columns not required for TADA workflow where all values are equal to
NA.
WQP_clean <- TADA_ConvertSpecialChars(WQP_clean, col = "TADA.ResultMeasureValue", clean = TRUE)TADA_RunKeyFlagFunctions is a shortcut function to run important TADA flagging functions. See ?function documentation for TADA_FlagResultUnit, TADA_FlagFraction, TADA_FlagMeasureQualifierCode, and TADA_FlagSpeciation for more information.
WQP_clean <- TADA_RunKeyFlagFunctions(
WQP_clean,
clean = TRUE
)Another set of TADA flagging functions,
TADA_FlagAboveThreshold and
TADA_FlagBelowThreshold, can be used to check results
against national lower and upper thresholds. For these, we will set
clean = FALSE and flaggedonly = TRUE so that it returns only flagged
results in the review dataframe returned. We will keep these in our
“clean” dataframe for now.
WQP_flag_reviewabove <- TADA_FlagAboveThreshold(WQP_clean, clean = FALSE, flaggedonly = TRUE)
WQP_flag_reviewbelow <- TADA_FlagBelowThreshold(WQP_clean, clean = FALSE, flaggedonly = TRUE)Remove intermediate variables.
rm(WQP_flag_reviewabove, WQP_flag_reviewbelow)Let’s take another look at all unique values in the TADA.ComparableDataIdentifier column and see how how many results are associated with each. TADA.ComparableDataIdentifier concatenates TADA.CharacteristicName, TADA.ResultSampleFractionText, TADA.MethodSpeciationName, and TADA.ResultMeasure.MeasureUnitCode.
# use TADA_FieldValuesTable to create a table of the number of results per TADA.ComparableDataIdentifier
chars <- TADA_FieldValuesTable(
WQP_clean,
field = "TADA.ComparableDataIdentifier",
characteristicName = "null"
)
chars_before <- unique(WQP_clean$TADA.ComparableDataIdentifier)
DT::datatable(chars, fillContainer = TRUE)Scroll through the table and check to see if there any synonyms. It
may be possible that some of these can be automatically harmonized using
TADA_HarmonizeSynonyms so their results can be directly
compared.
Let’s give it a try.
WQP_clean <- TADA_HarmonizeSynonyms(WQP_clean)How many unique TADA.ComparableDataIdentifier’s do we have now? In this example, there were no synonyms.
chars_after <- unique(WQP_clean$TADA.ComparableDataIdentifier)Remove intermediate variables.
rm(chars_before, chars_after)Create a pie chart.
TADA_FieldValuesPie(
WQP_clean,
field = "TADA.CharacteristicName",
characteristicName = "null"
)Select characteristic
Let’s filter the data and focus on a one characteristic of interest.
# Select characteristics of interest
WQP_clean_subset <- WQP_clean |>
dplyr::filter(TADA.CharacteristicName %in% "ESCHERICHIA COLI")Remove intermediate variables. We will focus on the subset from now on.
rm(WQP_clean, chars)Integrate ATTAINS and map
In this section, we will associate geospatial data from ATTAINS with the WQP data. Our initial WQP data pull was done using a shapefile for Assessment Unit CT6400-00-1-L5_01. TADA functions can pull in additional ATTAINS meta data for this assessment unit. We can also generate a new table to give us some information about the individual monitoring locations within this assessment unit.
- TADA_CreateATTAINSAUMLCrosswalk() automates matching of WQP monitoring locations with ATTAINS assessment units that fall within (intersect) the same NHDPlus catchment (details)
- The function uses high resolution NHDPlus catchments by default because 80% of state submitted assessment units in ATTAINS were developed based on high res NHD; users can select med-res if applicable to their use case
WQP_clean_subset_spatial <- TADA_CreateATTAINSAUMLCrosswalk(
WQP_clean_subset,
return_nearest = TRUE,
return_sf = TRUE
)
# Adds ATTAINS info to df
WQP_clean_subset <- WQP_clean_subset_spatial$TADA_with_ATTAINSView catchments and assessment units on map
ATTAINS_map <- TADA_ViewATTAINS(WQP_clean_subset_spatial,
ref_icons = FALSE
)
ATTAINS_mapRemove intermediate variables:
rm(ATTAINS_map)Create table of monitoring location identifiers and AUs.
ML_AU_crosswalk <- WQP_clean_subset |>
dplyr::select(TADA.MonitoringLocationIdentifier, ATTAINS.AssessmentUnitIdentifier, ATTAINS.AssessmentUnitName, TADA.CharacteristicName) |>
dplyr::distinct()Remove intermediate variables. Let’s keep going with WQP_clean_subset.
rm(ML_AU_crosswalk, WQP_clean_subset_spatial)TADA_RetainRequired removes all duplicate columns where
TADA has created a new column with a TADA prefix. It retains all TADA
prefixed columns as well as other original fields that are either
required by other TADA functions or are commonly used filters.
WQP_clean_subset <- TADA_RetainRequired(WQP_clean_subset)Exploratory analysis
Review unique TADA.ComparableDataIdentifier’s
unique(WQP_clean_subset$TADA.ComparableDataIdentifier)Let’s check if any results are above the EPA 304A recommended maximum criteria magnitude (see: 2012 Recreational Water Quality Criteria Fact Sheet).
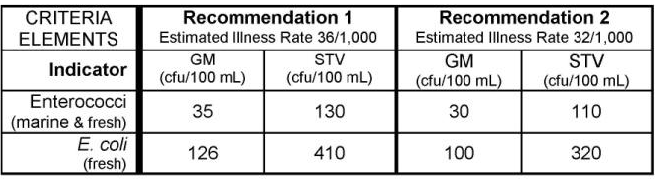
If interested, you can find other state, tribal, and EPA 304A criteria in EPA’s Criteria Search Tool.
Let’s check if any individual results exceed 320 CFU/100mL (the magnitude component of the EPA recommendation 2 criteria for ESCHERICHIA COLI).
# add column with comparison to criteria mag (excursions)
WQP_clean_subset <- WQP_clean_subset |>
sf::st_drop_geometry() |>
dplyr::mutate(meets_criteria_mag = ifelse(TADA.ResultMeasureValue <= 320, "Yes", "No"))
# review
WQP_clean_subset_review <- WQP_clean_subset |>
dplyr::select(
MonitoringLocationIdentifier, OrganizationFormalName, ActivityStartDate, TADA.ResultMeasureValue,
meets_criteria_mag
)
DT::datatable(WQP_clean_subset_review, fillContainer = TRUE)Generate stats table. Review percentiles. Less than 5% of results fall above 10 CFU/100mL, and over 98% of results fall below 265.2 CFU/100m.
WQP_clean_subset_stats <- WQP_clean_subset |>
sf::st_drop_geometry() |>
TADA_Stats()Generate a scatterplot. One result value is above the threshold.
TADA_Scatterplot(WQP_clean_subset, id_cols = "TADA.ComparableDataIdentifier") |>
plotly::add_lines(
y = 320,
x = c(min(WQP_clean_subset$ActivityStartDate), max(WQP_clean_subset$ActivityStartDate)),
inherit = FALSE,
showlegend = FALSE,
line = list(color = "red"),
hoverinfo = "none"
)Generate a histogram.
TADA_Histogram(WQP_clean_subset, id_cols = "TADA.ComparableDataIdentifier")TADA_Boxplot can be useful for identifying skewness and
percentiles.
TADA_Boxplot(WQP_clean_subset, id_cols = "TADA.ComparableDataIdentifier")TADA_RetainRequired removes extra columns. Enter
?TADA_RetainRequired into the console for more details.
WQP_clean_subset_final <- TADA_RetainRequired(WQP_clean_subset)Record end time
end.time <- Sys.time()
end.time - start.timeReproducible and Documented
This workflow is reproducible and the decisions at each step are well documented. This means that it is easy to go back and review every step, understand the decisions that were made, make changes as necessary, and run it again.