TADA Module 1: Water Quality Portal Data Discovery and Cleaning
TADA Team
2026-07-28
Source:vignettes/TADAModule1.Rmd
TADAModule1.RmdOverview
This vignette walks through how to use the TADA R Package to discover and clean (i.e., wrangle, Quality Assure and Quality Control (QAQC), and harmonize) Water Quality Portal (WQP) data from multiple organizations.
Install and Load the EPATADA R Package
First, install and load the remotes package specifying the repo. This is needed before installing EPATADA because it is only available on GitHub (not CRAN).
install.packages("remotes")
# Load the remotes library
library(remotes)Next, install and load TADA using the remotes package. TADA R Package dependencies will also be downloaded automatically from CRAN with the TADA install. You may be prompted in the console to update dependency packages that have more recent versions available. If you see this prompt, it is recommended to update all of them (enter 1 into the console).
remotes::install_github("USEPA/EPATADA",
ref = "develop",
dependencies = TRUE
)Finally, use the library() function to load the TADA R Package into your R session.
TADA_DataRetrieval
WQP data is retrieved and processed for compatibility with TADA. This function, TADA_DataRetrieval, builds on USGS’s dataRetrieval R package functions. It joins three WQP profiles: Site, Sample Results (physical/chemical metadata), and Project. In addition, it changes all data in the Characteristic, Speciation, Fraction, and Unit fields to uppercase and addresses result values that include special characters.
This function accepts the same inputs as the dataRetrieval
readWQPdata function. readWQPdata does not
restrict the characteristics pulled from Water Quality Portal
(WQP).
Data retrieval filters include:
startDate
endDate
characteristicName
sampleMedia
siteType
statecode (see list of possible state and territory abbreviations here)
countycode
siteid
organization
project
huc
characteristicType
providers
In addition to these filters, TADA_DataRetrieval accepts additional
geospatial-related filters that are not included in the dataRetrieval
readWQPdata function:
aoi_sf
tribal_area_type
tribe_name_parcel (Note: The TADA_TribalOptions function can be used to narrow down options for use with this tribe_name_parcel filter option. See ?TADA_TribalOptions for more info).
After data is downloaded using the filters above, the default TADA_DataRetrieval function also automatically runs the TADA_AutoClean function. If desired, users can set applyautoclean = FALSE in their TADA_DataRetrieval calls. In this example, we will set applyautoclean = FALSE and run it as a separate step in the workflow.
Tips:
-
All the query filters for the WQP work as an AND but within the fields there are ORs. For example:
Characteristics: If you choose pH & DO - it’s an OR. This means you will retrieve both pH OR DO data if available.
States: Similarly, if you choose VA and IL, it’s an OR. This means you will retrieve both VA OR IL data if available.
Combinations of fields are ANDs, such as State/VA AND Characteristic/DO”. This means you will receive all DO data available in VA.
“Characteristic” and “Characteristic Type” also work as an AND. This means that the Characteristic must fall within the CharacteristicGroup if both filters are being used, if not you will get an error.
The “siteid” is a general term WQP uses to describe both Site IDs from USGS databases and Monitoring Location Identifiers (from WQX). Each monitoring location in the Water Quality Portal (WQP) has a unique Monitoring Location Identifier, regardless of the database from which it derives. The Monitoring Location Identifier from the WQP is the concatenated Organization Identifier plus the Site ID number. Site IDs that only include a number are only unique identifiers for monitoring locations within USGS NWIS or EPA’s WQX databases separately.
The aoi_sf and tribal arguments are meant to be used on their own. For example, if both an aoi_sf argument and tribal information are provided an error is returned because it’s unclear what the priority location should be for the query. Similarly, aoi_sf and tribal_area_type are not meant to be used with location-related filters (e.g., statecode, siteid). In these instances a warning is returned but the query proceeds by using only the aoi_sf or tribal_area_type information.
Additional resources:
Review function documentation by entering the following code into the console: ?TADA_DataRetrieval
Use the code below to download data from the WQP using TADA_DataRetrieval. Edit the code chunk below to define your own WQP query inputs.
Downloads using TADA_DataRetrieval will have the same columns each time, but be aware that data are uploaded to the Water Quality Portal by individual organizations, which may or may not follow the same conventions. Data and metadata quality are not guaranteed! Carefully explore data to make sure it meets your quality assurance requirements.
Note: TADA_DataRetrieval (by leveraging dataRetrieval), automatically converts the date times to UTC. It also automatically converts field formats to dates, datetimes, and numerics based on a standard algorithm.
Enter ?TADA_DataRetrieval into the console to review example queries and additional information.
This example includes monitoring data collected from Jan 2018 to Jan 2019 by six organizations: 1) Red Lake Band of Chippewa Indians, 2) Sac & Fox Nation, 3) Pueblo of Pojoaque, 4) Minnesota Chippewa Tribe (Fond du Lac Band), 5) Pueblo of Tesuque, and 6) The Chickasaw Nation.
TADAProfile <- TADA_DataRetrieval(organization = c("REDLAKE_WQX", "SFNOES_WQX", "PUEBLO_POJOAQUE", "FONDULAC_WQX", "PUEBLOOFTESUQUE", "CNENVSER"), startDate = "2018-01-01", endDate = "2019-01-01", applyautoclean = FALSE, ask = FALSE)We will move forward with this example in the remainder of the vignette.
We will first use a subset of this example to demonstrate using new TADA_DataRetrieval options that allow for spatial or tribe-specific queries:
Focusing just on the “PUEBLO_POJOAQUE” organization, rerun the example above:
TADAProfile_single <- TADA_DataRetrieval(
organization = "PUEBLO_POJOAQUE",
startDate = "2018-01-01",
endDate = "2019-01-01",
applyautoclean = FALSE,
ask = FALSE
)The same results can now be obtained using a combination of the tribal_area_type and tribe_name_parcel arguments. Both must be used together. The tribal_area_type argument indicates which one of four layer datasets (“Alaska Native Allotments”, “American Indian Reservations”, “Off-reservation Trust Lands”, or “Oklahoma Tribal Statistical Areas”) of tribal land data to query within. Note that “Alaska Native Villages” and “Virginia Federally Recognized Tribes” layers will not return a successful query. These four tribal_area_type layer options include multiple tribes. Therefore, tribe_name_parcel is where users can enter the specific name of the tribal land of interest as listed in the layer. In this example for Pueblo of Pojoaque, running TADA_TribalOptions(“American Indian Reservations”) could be used here to determine the correct spelling for this argument, “Pueblo of Pojoaque, New Mexico”, as listed in the TRIBE_NAME column.
# Review TRIBE_NAME column to get name format for the TADA_DataRetrieval tribe_name_parcel function input
TRIBE_NAME <- TADA_TribalOptions("American Indian Reservations")
TADAProfile_tribal <- TADA_DataRetrieval(
tribal_area_type = "American Indian Reservations",
tribe_name_parcel = "Pueblo of Pojoaque, New Mexico",
startDate = "2018-01-01",
endDate = "2019-01-01",
applyautoclean = FALSE,
ask = FALSE
)
# They are equivalent:
all.equal(data.frame(TADAProfile_single), data.frame(TADAProfile_tribal))Additionally, the aoi_sf argument can be used to provide an sf spatial object as a query filter. We can match the output of the two short Pueblo of Pojoaque examples above, using tigris::native_areas to acquire Census Bureau spatial data:
TADAProfile_spatial <- TADA_DataRetrieval(
aoi_sf = tigris::native_areas() |> dplyr::filter(NAMELSAD == "Pueblo of Pojoaque"),
startDate = "2018-01-01",
endDate = "2019-01-01",
applyautoclean = FALSE,
ask = FALSE
)
all.equal(data.frame(TADAProfile_single), data.frame(TADAProfile_spatial))Note: In this example the output data is identical from these three input methods. However, in some instances this may not be the case. This is because the tribal_area_type method is based on spatial data and so spatial boundaries must be taken into account when comparing query results. The same applies when using aoi_sf results.
Let’s repeat this process for Red Lake Band of Chippewa Indians. In this case, we will get additional observations from other organizations who are sampling with the tribal boundary. This is one great benefit of this query option! There is additional data available that may be useful but is missed if only the organization query filter is used.
TADAProfile_single_2 <- TADA_DataRetrieval(
organization = "REDLAKE_WQX",
startDate = "2018-01-01",
endDate = "2019-01-01",
applyautoclean = FALSE,
ask = FALSE
)
TADAProfile_tribal_2 <- TADA_DataRetrieval(
tribal_area_type = "American Indian Reservations",
tribe_name_parcel = "Red Lake Band of Chippewa Indians, Minnesota",
startDate = "2018-01-01",
endDate = "2019-01-01",
applyautoclean = FALSE,
ask = FALSE
)
# Review unique organizations
unique(TADAProfile_single_2$OrganizationFormalName)
unique(TADAProfile_tribal_2$OrganizationFormalName)USGS dataRetrieval
Uncomment below (optional) if you would like to review differences between the profiles you would get using USGS’s readWQPdata vs. EPA’s TADA_DataRetrieval (compare dataRetrieval_example to TADAProfile). The profiles are different because TADA_DataRetrieval automatically joins in data from multiple WQP profiles, and does some additional data cleaning as part of the data retrieval process.
# dataRetrieval_example <- dataRetrieval::readWQPdata(organization = c("REDLAKE_WQX", "SFNOES_WQX", "PUEBLO_POJOAQUE", "FONDULAC_WQX", "PUEBLOOFTESUQUE", "CNENVSER"), startDate = "2018-01-01", endDate = "2019-01-01", ignore_attributes = TRUE)Big Data Queries
If you need to download a large amount of data from across a large area, the TADA_DataRetrieval function now handles this automatically. Whereas in the past there was a second function (TADA_BigDataRetrieval) to do this, the standard TADA_DataRetrieval function now checks the number of results in each query and uses similar methods as TADA_BigDataRetrieval when necessary.
The function does multiple synchronous data calls to the WQP (waterqualitydata.us). It uses the WQP summary service to limit the sites downloaded to only those with relevant data. It pulls back data from set number of stations at a time and then joins the data back together to produce a single TADA compatible dataframe as the output.
Users can leverage the new maxrecs function input for TADA_DataRetrieval to specify the maximum number of records to query at once (i.e., without breaking into smaller queries). The default is 250000 records.
TADA_DataRetrieval now also prompts the user (when ask = TRUE) to confirm that they want to download the dataset. As part of this prompt the expected number of rows of data are provided to help in making the decision. As the downloads occur, a progress bar is shown as well.
See ?TADA_DataRetrieval for more details. WARNING, some of the examples below can take multiple HOURS to run. The total run time depends on your query inputs.
# AK_AL_WaterTemp <- TADA_DataRetrieval(startDate = "2000-01-01", endDate = "2022-12-31", characteristicName = "Temperature, water", statecode = c("AK","AL"))
#
# AllWaterTemp <- TADA_DataRetrieval(characteristicName = "Temperature, water")
#
# AllPhosphorus <- TADA_DataRetrieval(characteristicName = "Phosphorus")
#
# AllCT <- TADA_DataRetrieval(statecode = "CT")Filter data based on media type
Some TADA users are interested in using WQP data for surface water only or for analysis of some non-water data. The TADA_MediaFilter function can assist in identifying results of interest. Multiple columns are used to identify groundwater results as different organizations may populate different combinations of fields in order to identify a result as groundwater.
This function identifies surface water, groundwater, and sediment results. Users can specify whether all results should be returned with a new column, TADA.Media.Flag, identifying if the result should be included in further analysis or if only results that should be in included are returned.
The defaults are to include surface water, exclude groundwater and sediment, and to return only the results that should be used for analysis (clean = TRUE). This is shown in the active example below. If you would like to see all results with the TADA.Media.Flag column, you can uncomment the example where clean = FALSE.
If you are not interested in using TADA_MediaFilter, but would like to filter by activity media, uncomment the example to filter for water data only by using dplyr::filter() with TADA.ActivityMediaName.
# Filter to retain only results for use in analysis
TADAProfile <- TADA_MediaFilter(TADAProfile,
clean = TRUE,
surface_water = FALSE,
ground_water = TRUE,
sediment = TRUE,
other = TRUE
)
# Add TADA.Media.Flag column to identify which results should be used for analysis
# TADAProfile <- TADA_MediaFilter(TADAProfile, clean = FALSE)
# Remove data for non-water media types, alternate workflow without using TADA_MediaFilter()
# TADAProfile <- dplyr::filter(TADAProfile, TADA.ActivityMediaName == "WATER")TADA_AutoClean
Now TADA_AutoClean can be run on a smaller dataset after unnecessary results have been removed. It performs the following functions on the data retrieved from the WQP:
TADA_ConvertSpecialChars - converts result value columns to numeric and flags non-numeric values that could not be converted.
TADA_ConvertResultUnits - unifies result units for easier quality control and review
TADA_ConvertDepthUnits - converts depth units to a consistent unit (meters).
TADA_IDCensoredData - categorizes detection limit data and identifies mismatches in result detection condition and result detection limit type.
Other helpful actions - converts important text columns to all upper-case letters, removes exact duplicates, and uses WQX format rules to harmonize specific NWIS metadata conventions (e.g. move characteristic speciation from the TADA.ResultMeasure.MeasureUnitCode column to the TADA.MethodSpeciationName column)
As a general rule, TADA functions do not change any contents in the WQP-served columns. Instead, they add new columns with the prefix “TADA.” The following columns are numeric versions of their WQP origins:
- TADA.ResultMeasureValue
- TADA.DetectionQuantitationLimitMeasure.MeasureValue
- TADA.LatitudeMeasure
- TADA.LongitudeMeasureThese functions also add the columns TADA.ResultMeasureValueDataTypes.Flag and TADA.DetectionQuantitationLimitMeasure.MeasureValueDataTypes.Flag, which provide information about the result values that is needed to address censored data later on (i.e., nondetections). Specifically, these new columns flag if special characters are included in result values, and specifies what the special characters are.
# run TADA_AutoClean on filtered dataset to convert special characters, result units, and depth units and identify censored data.
TADAProfile <- TADA_AutoClean(TADAProfile)Review all column names in the TADA Profile to familiarize yourself with the dataset after TADA_AutoClean has added additional TADA prefixed columns. TADA_SummarizeColumn summarizes the data set based on the user specified column and returns a dataframe displaying the number of sites and number of records for each unique value in the specified column. The example below uses TADA.CharacteristicName.
# View column names for TADAProfile
colnames(TADAProfile)## [1] "ResultIdentifier"
## [2] "ActivityTypeCode"
## [3] "ActivityMediaName"
## [4] "TADA.ActivityMediaName"
## [5] "ActivityMediaSubdivisionName"
## [6] "CountryCode"
## [7] "StateCode"
## [8] "CountyCode"
## [9] "MonitoringLocationName"
## [10] "TADA.MonitoringLocationName"
## [11] "MonitoringLocationTypeName"
## [12] "TADA.MonitoringLocationTypeName"
## [13] "MonitoringLocationDescriptionText"
## [14] "LatitudeMeasure"
## [15] "TADA.LatitudeMeasure"
## [16] "LongitudeMeasure"
## [17] "TADA.LongitudeMeasure"
## [18] "HorizontalCoordinateReferenceSystemDatumName"
## [19] "HUCEightDigitCode"
## [20] "MonitoringLocationIdentifier"
## [21] "TADA.MonitoringLocationIdentifier"
## [22] "ResultSampleFractionText"
## [23] "TADA.ResultSampleFractionText"
## [24] "CharacteristicName"
## [25] "TADA.CharacteristicName"
## [26] "SubjectTaxonomicName"
## [27] "MethodSpeciationName"
## [28] "TADA.MethodSpeciationName"
## [29] "TADA.ComparableDataIdentifier"
## [30] "ActivityStartDate"
## [31] "ActivityStartTime.Time"
## [32] "ActivityStartTime.TimeZoneCode"
## [33] "ActivityStartDateTime"
## [34] "ResultMeasureValue"
## [35] "ResultMeasure.MeasureUnitCode"
## [36] "TADA.ResultMeasureValue"
## [37] "TADA.ResultMeasure.MeasureUnitCode"
## [38] "TADA.WQXResultUnitConversion"
## [39] "ResultValueTypeName"
## [40] "TADA.ResultMeasureValueDataTypes.Flag"
## [41] "ResultDetectionConditionText"
## [42] "DetectionQuantitationLimitTypeName"
## [43] "DetectionQuantitationLimitMeasure.MeasureValue"
## [44] "DetectionQuantitationLimitMeasure.MeasureUnitCode"
## [45] "TADA.DetectionQuantitationLimitMeasure.MeasureValue"
## [46] "TADA.DetectionQuantitationLimitMeasure.MeasureUnitCode"
## [47] "TADA.DetectionQuantitationLimitMeasure.MeasureValueDataTypes.Flag"
## [48] "ResultDepthHeightMeasure.MeasureValue"
## [49] "TADA.ResultDepthHeightMeasure.MeasureValue"
## [50] "TADA.ResultDepthHeightMeasure.MeasureValueDataTypes.Flag"
## [51] "ResultDepthHeightMeasure.MeasureUnitCode"
## [52] "TADA.ResultDepthHeightMeasure.MeasureUnitCode"
## [53] "ResultDepthAltitudeReferencePointText"
## [54] "ActivityRelativeDepthName"
## [55] "ActivityDepthHeightMeasure.MeasureValue"
## [56] "TADA.ActivityDepthHeightMeasure.MeasureValue"
## [57] "TADA.ActivityDepthHeightMeasure.MeasureValueDataTypes.Flag"
## [58] "ActivityDepthHeightMeasure.MeasureUnitCode"
## [59] "TADA.ActivityDepthHeightMeasure.MeasureUnitCode"
## [60] "ActivityTopDepthHeightMeasure.MeasureValue"
## [61] "TADA.ActivityTopDepthHeightMeasure.MeasureValue"
## [62] "TADA.ActivityTopDepthHeightMeasure.MeasureValueDataTypes.Flag"
## [63] "ActivityTopDepthHeightMeasure.MeasureUnitCode"
## [64] "TADA.ActivityTopDepthHeightMeasure.MeasureUnitCode"
## [65] "ActivityBottomDepthHeightMeasure.MeasureValue"
## [66] "TADA.ActivityBottomDepthHeightMeasure.MeasureValue"
## [67] "TADA.ActivityBottomDepthHeightMeasure.MeasureValueDataTypes.Flag"
## [68] "ActivityBottomDepthHeightMeasure.MeasureUnitCode"
## [69] "TADA.ActivityBottomDepthHeightMeasure.MeasureUnitCode"
## [70] "ResultTimeBasisText"
## [71] "StatisticalBaseCode"
## [72] "ResultFileUrl"
## [73] "ResultAnalyticalMethod.MethodName"
## [74] "ResultAnalyticalMethod.MethodDescriptionText"
## [75] "ResultAnalyticalMethod.MethodIdentifier"
## [76] "ResultAnalyticalMethod.MethodIdentifierContext"
## [77] "ResultAnalyticalMethod.MethodUrl"
## [78] "SampleCollectionMethod.MethodIdentifier"
## [79] "SampleCollectionMethod.MethodIdentifierContext"
## [80] "SampleCollectionMethod.MethodName"
## [81] "SampleCollectionMethod.MethodDescriptionText"
## [82] "SampleCollectionEquipmentName"
## [83] "MeasureQualifierCode"
## [84] "ResultStatusIdentifier"
## [85] "ResultCommentText"
## [86] "ActivityCommentText"
## [87] "HydrologicCondition"
## [88] "HydrologicEvent"
## [89] "DataQuality.PrecisionValue"
## [90] "DataQuality.BiasValue"
## [91] "DataQuality.ConfidenceIntervalValue"
## [92] "DataQuality.UpperConfidenceLimitValue"
## [93] "DataQuality.LowerConfidenceLimitValue"
## [94] "SamplingDesignTypeCode"
## [95] "LaboratoryName"
## [96] "ResultLaboratoryCommentText"
## [97] "ActivityIdentifier"
## [98] "OrganizationIdentifier"
## [99] "OrganizationFormalName"
## [100] "ProjectName"
## [101] "ProjectDescriptionText"
## [102] "ProjectIdentifier"
## [103] "ProjectFileUrl"
## [104] "QAPPApprovedIndicator"
## [105] "QAPPApprovalAgencyName"
## [106] "AquiferName"
## [107] "AquiferTypeName"
## [108] "LocalAqfrName"
## [109] "ConstructionDateText"
## [110] "WellDepthMeasure.MeasureValue"
## [111] "WellDepthMeasure.MeasureUnitCode"
## [112] "WellHoleDepthMeasure.MeasureValue"
## [113] "WellHoleDepthMeasure.MeasureUnitCode"
## [114] "ProviderName"
## [115] "LastUpdated"
## [116] "ActivityDepthAltitudeReferencePointText"
## [117] "ActivityEndDate"
## [118] "ActivityEndTime.Time"
## [119] "ActivityEndTime.TimeZoneCode"
## [120] "ActivityEndDateTime"
## [121] "ActivityConductingOrganizationText"
## [122] "SampleAquifer"
## [123] "ActivityLocation.LatitudeMeasure"
## [124] "ActivityLocation.LongitudeMeasure"
## [125] "ResultWeightBasisText"
## [126] "ResultTemperatureBasisText"
## [127] "ResultParticleSizeBasisText"
## [128] "USGSPCode"
## [129] "BinaryObjectFileName"
## [130] "BinaryObjectFileTypeCode"
## [131] "AnalysisStartDate"
## [132] "ResultDetectionQuantitationLimitUrl"
## [133] "LabSamplePreparationUrl"
## [134] "ActivityStartTime.TimeZoneCode_offset"
## [135] "ActivityEndTime.TimeZoneCode_offset"
## [136] "SourceMapScaleNumeric"
## [137] "HorizontalAccuracyMeasure.MeasureValue"
## [138] "HorizontalAccuracyMeasure.MeasureUnitCode"
## [139] "HorizontalCollectionMethodName"
## [140] "VerticalMeasure.MeasureValue"
## [141] "VerticalMeasure.MeasureUnitCode"
## [142] "VerticalAccuracyMeasure.MeasureValue"
## [143] "VerticalAccuracyMeasure.MeasureUnitCode"
## [144] "VerticalCollectionMethodName"
## [145] "VerticalCoordinateReferenceSystemDatumName"
## [146] "FormationTypeText"
## [147] "ProjectMonitoringLocationWeightingUrl"
## [148] "DrainageAreaMeasure.MeasureValue"
## [149] "DrainageAreaMeasure.MeasureUnitCode"
## [150] "ContributingDrainageAreaMeasure.MeasureValue"
## [151] "ContributingDrainageAreaMeasure.MeasureUnitCode"
## [152] "SampleTissueAnatomyName"
# Review the number of sites and number of records for each CharacteristicName in TADAProfile
TADAProfile_CharSummary <- TADA_SummarizeColumn(TADAProfile, "TADA.CharacteristicName")
# View TADAProfile_CharSummary
TADAProfile_CharSummary## # A tibble: 104 × 3
## TADA.CharacteristicName n_sites n_records
## <chr> <int> <int>
## 1 .ALPHA.-ENDOSULFAN 6 7
## 2 .ALPHA.-HEXACHLOROCYCLOHEXANE 6 7
## 3 .BETA.-ENDOSULFAN 6 7
## 4 .BETA.-HEXACHLOROCYCLOHEXANE 6 7
## 5 .DELTA.-HEXACHLOROCYCLOHEXANE 6 7
## 6 ALDRIN 6 7
## 7 ALKALINITY, TOTAL 128 692
## 8 ALPHA PARTICLE 6 14
## 9 ALUMINUM 6 7
## 10 AMMONIA-NITROGEN 83 328
## # ℹ 94 more rowsInvalid coordinates
Review station locations and summary information using the TADA_OverviewMap function. TADA_OverviewMap counts the number of unique results, characteristics, and organizations at each monitoring location in the dataset and creates a tidy map for reviewing summary stats spatially. Larger point sizes indicate more results collected at a given site, while darker blue colors indicate more unique characteristics collected at the site. Users may click on a site to view a pop-up with this summary information, including the number of organizations that reported results at that site. This map may inform a user’s decision to remove/correct sites that are outside the US.
TADA_OverviewMap(TADAProfile)The TADA_FlagCoordinates function identifies and flags potentially invalid coordinate data. While its functionality is showcased here, it is always important to review any invalid outputs before cleaning to reduce the risk of leaving out usable data/sites.
Allowable values for clean_outsideUSA are “no”, “remove”, or “change sign”. The default is “no” which flags latitude and longitude coordinates outside the USA. Assigning clean_outsideUSA = “remove” will remove rows of data with coordinates outside the USA. And assigning clean_outsideUSA = “change sign” will flip the sign of latitude or longitude coordinates flagged as outside the USA. The “change sign” option should only be used when it is known that coordinates were entered with the wrong sign in WQX; additionally, the data owner should fix these incorrect coordinates in the raw data through the WQX - for assistance email the WQX help desk: WQX@epa.gov
Allowable values for clean_imprecise are TRUE or FALSE. The default is FALSE which flags rows of data with invalid or imprecise coordinates without removing them. Assigning clean_imprecise = TRUE will remove rows of data with invalid or imprecise coordinates.
Allowable values for flaggedonly are TRUE or FALSE. The default is FALSE which keeps all rows of data regardless of flag status. Assigning flaggedonly = TRUE filters the dataframe to show only rows of data which are flagged.
When clean_outsideUSA = “no” and/or clean_imprecise = FALSE, a column will be appended titled “TADA.InvalidCoordinates.Flag” with the following flags (if relevant to dataframe):
If the latitude is less than zero, the row will be flagged with “LAT_OutsideUSA”. (Exception for American Samoa)
If the longitude is greater than zero AND less than 145, the row will be flagged as “LONG_OutsideUSA”. (Exceptions for Guam and the Northern Mariana Islands)
If the latitude or longitude contains the string, “999”, the row will be flagged as invalid.
Finally, precision can be measured by the number of decimal places in the latitude and longitude provided. If either does not have any numbers to the right of the decimal point, the row will be flagged as “Imprecise”.
# flag only
TADAProfileClean1 <- TADA_FlagCoordinates(TADAProfile, clean_outsideUSA = "no", clean_imprecise = FALSE, flaggedonly = FALSE)
# review unique flags in TADAProfileClean1
unique(TADAProfileClean1$TADA.SuspectCoordinates.Flag)
# review unique MonitoringLocationIdentifiers in your flag dataframe
unique(TADAProfileClean1$MonitoringLocationIdentifier)
Unique_SuspectCoordinateFlags <- TADAProfileClean1 |>
dplyr::select(
"MonitoringLocationIdentifier",
"MonitoringLocationName",
"TADA.SuspectCoordinates.Flag",
"OrganizationIdentifier",
"TADA.LongitudeMeasure",
"TADA.LatitudeMeasure",
"MonitoringLocationTypeName",
"CountryCode",
"StateCode",
"CountyCode",
"HUCEightDigitCode",
"MonitoringLocationDescriptionText",
"ProjectName",
"ProjectIdentifier",
"OrganizationFormalName"
) |>
dplyr::distinct()
Unique_SuspectCoordinateFlags
# if needed, un-comment below to change the sign for all data for sites flagged as outside the USA. You can also set clean_imprecise = TRUE if you want to remove sites with imprecise lat/longs. Enter ?TADA_FlagCoordinates into the console for more details.
# TADAProfileClean1 <- TADA_FlagCoordinates(TADAProfile, clean_outsideUSA = "change sign", clean_imprecise = TRUE, flaggedonly = FALSE)Depth unit conversions
The TADA_ConvertDepthUnits function converts depth units to a consistent unit. Depth values and units are most commonly associated with lake data, and are populated in the ActivityDepthHeightMeasure, ActivityTopDepthHeightMeasure, ActivityBottomDepthHeightMeasure, and ResultDepthHeightMeasure Result Value/Unit columns.
Allowable values for ‘unit’ are either ‘m’ (meter), ‘ft’ (feet), or ‘in’ (inch). ‘unit’ accepts only one allowable value as an input. Default is unit = “m”.
Note that upon download using TADA_DataRetrieval, all depth columns are converted to meters by default. However, the user may choose to run the TADA_ConvertDepthUnits function on their dataset to convert to another unit. See function documentation for additional input options by entering the following code in the console: ?TADA_ConvertDepthUnits
# converts all depth profile data to meters
TADAProfileClean1 <- TADA_ConvertDepthUnits(TADAProfileClean1,
unit = "ft",
transform = TRUE
)Continuous (time series) data
Continuous data may (or may not) be suitable for integration with discrete water quality data for analyses. Therefore, the TADA_FlagContinuousData function was developed to flag rows with continuous data.
See function documentation for additional details by entering the following code in the console: ?TADA_FlagContinuousData
TADAProfileClean1 <- TADA_FlagContinuousData(TADAProfileClean1,
clean = FALSE,
flaggedonly = FALSE,
time_difference = 4
)
# uncomment below to create a dataframe of only the continuous data
# TADAProfile_onlycont <- TADA_FlagContinuousData(TADAProfileClean1, clean = FALSE, flaggedonly = TRUE, time_difference = 4)WQX Quality Assurance and Quality Control (QAQC) Service Result Flags
Run the following result functions to address suspect method, fraction, speciation, and unit metadata by characteristic. The default is clean = TRUE, which will remove suspect results. You can change this to clean = FALSE to flag results, but not remove them.
See documentation for more details:
-
?TADA_FlagMethod
When clean = FALSE, this function adds the following column to your dataframe: TADA.AnalyticalMethod.Flag. This column flags invalid TADA.CharacteristicName, ResultAnalyticalMethod/MethodIdentifier, and ResultAnalyticalMethod/MethodIdentifierContext combinations in your dataframe either “NonStandardized”, “Suspect”, or “Pass”.
When clean = TRUE, “Suspect” rows are removed from the dataframe and no column will be appended.
When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as “Suspect”; default is flaggedonly = FALSE.
-
?TADA_FlagSpeciation
-
When clean = “none”, this function adds the following column to your dataframe: TADA.MethodSpeciation.Flag. This column flags each TADA.CharacteristicName and MethodSpeciationName combination in your dataframe as either “NonStandardized”,
“Suspect”, or “Pass”.
When clean = “suspect_only”, only “Suspect” rows are removed from the dataframe. Default is clean = “suspect_only”.
When clean = “nonstandardized_only”, only “NonStandardized” rows are removed from the dataframe.
When clean = “both”, “Invalid” and “NonStandardized” rows are removed from the dataframe.
When clean = “none”, no rows are removed from the dataframe.
When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as “Suspect” or “NonStandardized”; default is flaggedonly = FALSE.
-
-
?TADA_FlagResultUnit
When clean = FALSE, the following column will be added to your dataframe: TADA.ResultUnit.Flag. This column flags each TADA.CharacteristicName, TADA.ActivityMediaName, and TADA.ResultMeasure.MeasureUnitCode combination in your dataframe as either “NonStandardized”, “Invalid”, or “Valid”.
When clean = TRUE, “Suspect” rows are removed from the dataframe and no column will be appended.
When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as “Suspect”; default is flaggedonly = FALSE.
-
?TADA_FlagFraction
- When clean = FALSE, this function adds the following column to your dataframe: TADA.SampleFraction.Flag. This column flags each TADA.CharacteristicName and TADA.ResultSampleFractionText combination in your dataframe as either “NonStandardized”, “Suspect”, or “Pass”.
- When clean = TRUE, “Suspect” rows are removed from the dataframe and no column will be appended.
- When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as “Suspect”; default is flaggedonly = FALSE.
TADAProfileClean2 <- TADA_FlagMethod(TADAProfileClean1, clean = TRUE)
TADAProfileClean2 <- TADA_FlagFraction(TADAProfileClean2, clean = TRUE)
TADAProfileClean2 <- TADA_FlagSpeciation(TADAProfileClean2, clean = "suspect_only")
TADAProfileClean2 <- TADA_FlagResultUnit(TADAProfileClean2, clean = "suspect_only")WQX national upper and lower thresholds
Run the following code to flag or remove results that are above or below the national upper and lower bound for each characteristic and unit combination. See documentation for more details:
-
?TADA_FlagAboveThreshold
When clean = FALSE, the following column is added to your dataframe: TADA.ResultValueAboveUpperThreshold.Flag. This column flags rows with data that are above the upper WQX threshold. The default is clean = FALSE.
When clean = TRUE, data that is above the upper WQX threshold is removed from the dataframe.
When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as above the upper WQX threshold; default is flaggedonly = FALSE.
-
?TADA_FlagBelowThreshold
When clean = FALSE, the following column is added to your dataframe: TADA.ResultValueBelowLowerThreshold.Flag. This column flags rows with data that are below the lower WQX threshold. The default is clean = FALSE.
When clean = TRUE, data that is below the lower WQX threshold is removed from the dataframe.
When flaggedonly = TRUE, the dataframe is filtered to only the rows flagged as below the lower WQX threshold; default is flaggedonly = FALSE.
TADAProfileClean3 <- TADA_FlagAboveThreshold(TADAProfileClean2, clean = TRUE)
TADAProfileClean3 <- TADA_FlagBelowThreshold(TADAProfileClean3, clean = TRUE)
rm(TADAProfileClean1, TADAProfile_CharSummary)Potential duplicates
Sometimes multiple organizations submit the exact same data to Water Quality Portal (WQP), which can affect water quality analyses and assessments. Similarly, organizations occasionally submit the same data multiple times to the Portal. The following functions check for and identify data that may be duplicates based on date, time, characteristic, result value, and a distance buffer. Each pair or group of potential duplicate rows is flagged with a unique ID. For more information, review the documentation by entering the following into the console:
- ?TADA_FindPotentialDuplicatesSingleOrg
TADAProfileClean3 <- TADA_FindPotentialDuplicatesSingleOrg(TADAProfileClean3,
clean = F)
# filter to keep only unique rows
TADAProfileClean3 <- TADA_FindPotentialDuplicatesSingleOrg(TADAProfileClean3,
clean = T)- ?TADA_FindPotentialDuplicatesMultipleOrgs
TADAProfileClean3 <- TADA_FindPotentialDuplicatesMultipleOrgs(
TADAProfileClean3,
dist_buffer = 100,
org_hierarchy = "none"
)
# filter to keep only unique rows using TADA.ResultSelectedMultipleOrgs
TADAProfileClean3 <- dplyr::filter(
TADAProfileClean3,
TADA.ResultSelectedMultipleOrgs == "Y"
)Review QAPP information
The TADA_FindQAPPApproval function checks data for an approved QAPP.
This function checks to see if there is any information in the column “QAPPApprovedIndicator”. Some organizations submit data for this field to indicate if the data produced has an approved Quality Assurance Project Plan (QAPP) or not. In this field, Y indicates yes, N indicates no.
This function has three default inputs: clean = TRUE, cleanNA = FALSE, and flaggedonly = FALSE. These defaults remove rows of data where the QAPPApprovedIndicator equals “N”.
Users could alternatively remove both Ns and NAs using the inputs clean = TRUE, cleanNA = TRUE, and flaggedonly = FALSE.
Additionally, users could filter to show only Ns and NAs by using the inputs clean = FALSE, cleanNA = FALSE, and flaggedonly = TRUE.
If clean = FALSE, cleanNA = FALSE, and flaggedonly = FALSE, the function will not do anything.
TADAProfileClean3 <- TADA_FindQAPPApproval(TADAProfileClean3, clean = FALSE, cleanNA = FALSE)The TADA_FindQAPPDoc function checks to see if a QAPP Doc is Available
This function checks data submitted under the “ProjectFileUrl” column to determine if a QAPP document is available to review. When clean = FALSE, a column will be appended to flag results that do have an associated QAPP document URL provided. When clean = TRUE, rows that do not have an associated QAPP document are removed from the dataframe and no column will be appended. When flaggedonly = TRUE, the dataframe is filtered to show only rows that do not have an associated QAPP document. The defaults are clean = FALSE and flaggedonly = FALSE. This function should only be used to remove data if an accompanying QAPP document is required to use data in assessments.
TADAProfileClean3 <- TADA_FindQAPPDoc(TADAProfileClean3,
clean = FALSE
)Full Dataframe Filtering
In this section a TADA user will want to review the unique values in specific fields and may choose to remove data with particular values.
To start, review the list of common fields used for filtering, and the number of unique values in each field using the TADA_FieldCounts function.
This function returns counts for you entire dataframe for each of the following fields (if populated, columns that are populated only with NAs are not included in the output):
ActivityTypeCode
TADA.ActivityMediaName
ActivityMediaSubdivisionName
ActivityCommentText
MonitoringLocationTypeName
StateCode
OrganizationFormalName
TADA.CharacteristicName
HydrologicCondition
HydrologicEvent
BiologicalIntentName
MeasureQualifierCode
ActivityGroup
AssemblageSampledName
ProjectName
CharacteristicNameUserSupplied
DetectionQuantitationLimitTypeName
SampleTissueAnatomyName
LaboratoryName
# multiple options
# print table to console
TADA_FieldCounts(TADAProfileClean3)## Fields Count
## 1 TADA.ComparableDataIdentifier 63
## 2 TADA.CharacteristicName 46
## 3 SubjectTaxonomicName 13
## 4 OrganizationFormalName 6
## 5 TADA.ActivityType.Flag 3
## 6 TADA.MonitoringLocationTypeName 3
## 7 ActivityRelativeDepthName 3
## 8 ActivityMediaSubdivisionName 2
## 9 ResultStatusIdentifier 2
## 10 ResultValueTypeName 2
## 11 TADA.ActivityMediaName 1
## 12 HydrologicCondition 1
## 13 HydrologicEvent 1
## 14 SampleTissueAnatomyName 1
# create object of table
fieldCounts_Table <- TADA_FieldCounts(TADAProfileClean3)Next, choose a field from the list generated above to view a summary table or pie chart of the counts of unique values in that field using TADA_FieldValuesTable or TADA_FieldValuesPie. We’ll start with ActivityTypeCode.
TADA_FieldValuesTable(TADAProfileClean3, field = "ActivityTypeCode")## Value Count
## 1 Field Msr/Obs 14457
## 2 Sample-Routine 3127
## 3 Quality Control Sample-Field Replicate 143
## 4 Quality Control Sample-Equipment Blank 29
TADA_FieldValuesPie(TADAProfileClean3, field = "ActivityTypeCode")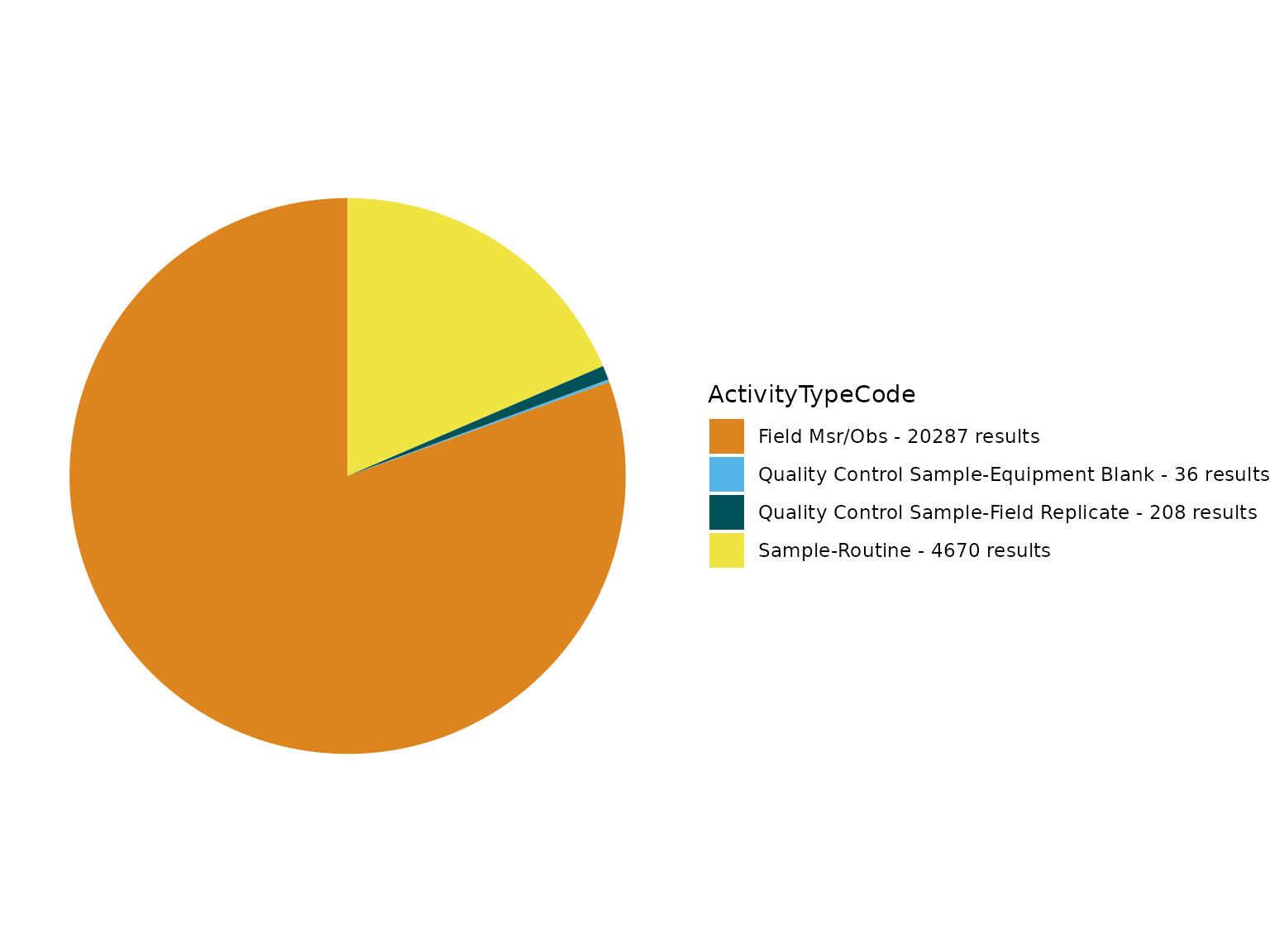
rm(TADAProfileClean2, fieldCounts_Table)The ActivityTypeCode field has multiple unique values. Before we remove the QC samples/measurements from this dataset to prepare for analyses, lets review flagged Quality Control (QC) values using the TADA_FindQCActivities function, which adds a new TADA TADA.ActivityType.Flag column.
For example, the new QC_replicate flag in TADA.ActivityType.Flag column indicates that the flagged rows include any of the following replicate values: - Quality Control Field Replicate Habitat Assessment - Quality Control Field Replicate Msr/Obs - Quality Control Field Replicate Portable Data Logger - Quality Control Field Replicate Sample-Composite - Quality Control Sample-Field Replicate
See WQX domain file to review all the ActivityTypeCode allowable values: https://cdx.epa.gov/wqx/download/DomainValues/ActivityType.CSV
# Review flagged QC samples using the TADA_FindQCActivities function:
# enter ?TADA_FindQCActivities into the console for more information
TADAProfileClean3a <- TADA_FindQCActivities(TADAProfileClean3,
clean = FALSE,
flaggedonly = TRUE
)
# Filter to review only data where the TADA.ActivityType.Flag = "QC_replicate"
TADAProfileClean3a <- dplyr::filter(TADAProfileClean3a, TADA.ActivityType.Flag == "QC_replicate")Now, let’s run TADA_PairReplicates to see if any replicates in this dataframe can be paired with their original (parent) samples/measurements.
We found over 100 replicates in this dataframe that have a paired parent sample/measurement (based on a 10-minute time window, which can be adjusted if desired). Enter ?TADA_PairReplicates into the console for more details.
What are replicate samples and how are they used in water analyses?
Replicate field samples are samples taken to assess the reproducibility of the sampling technique or analytical method. They are independently carried through all the steps of the sampling and measurement process in an identical manner to their associated routine field sample and used to measure the precision of the total sampling method.
Theoretically, the analysis of a replicate field sample should yield a very similar result as its associated routine field sample. If the results are not the same or acceptably similar, it could signal possible contamination or other issues in the sampling chain. However, water quality can vary at very small scales. So, the field replicate can mix up analytical precision with small scale variability. Field replicates tell you the potential for your method to yield the same results at a single time and place, to the extent that you are actually in exactly the same place, and the few seconds (or any defined time window) from one sample to the next does not matter, and the water isn’t moving. Be careful about labeling data as imprecise or bad based on this alone.
Users of TADA have noted that it would be useful to incorporate replicate field samples into water quality data analysis by (a) flagging routine field sample measurements whose associated replicate field sample measurements are outside of a user-defined window of precision (relative percent difference or absolute difference) and/or (b) averaging or randomly replacing routine field sample measurements with their associated replicate field sample measurements.
For now, users can perform these subsequent analyses outside of TADA. A two-stage data-quality-indicator, where low values should be within the absolute difference limit and high values within the Relative Percent Difference (RPD) limit, may be appropriate. RPD is the calculated difference (RPD) between the routine sample result and its associated replicate sample result. For example, if the RPD/CV exceeds 20% some water quality, analysts consider that to be a potentially concerning lack of precision, especially for non-particulate analytes. However, depending on the characteristic being analyzed and the sampling method, acceptable RPDs can vary widely. Therefore, it is best for the user to define their own level of RPD acceptability. In addition, a tiered approach may be more appropriate, where the widely used 20% RPD for measurements can be used for results above XX-times the detection limit, but also an absolute difference approach can be used for those result-values near the detection limit, or lower than the detection limit (e.g., phosphorus). An absolute difference approach is more appropriate when implementing RPD for samples close to the detection limit, as even small absolute differences might show up as large relative percent differences that “fail” the 20% RPD test.
For example, when nutrient concentrations are close to detection limit, it becomes impossible to have a low RPD. In this scenario, high RPDs are acceptable because if you stand back and look at ALL the data, and not just the replicates, these data may be agreeing perfectly well that nutrients are very low. DO NOT throw out data if RPD is >20%, unless you have good reason, or you will potentially bias your data toward high concentrations. QA procedures should not bias statistical analyses of the data. Note that a modest error in a measurement will have a much smaller effect than implementing a QA process that builds in bias.
# Run TADA_PairReplicates to add new TADA.ReplicateSampleID column
TADAProfileClean3b <- TADA_PairReplicates(TADAProfileClean3)
# Review unique values in TADA.ReplicateSampleID
unique(TADAProfileClean3b$TADA.ReplicateSampleID)## [1] NA "STORET-738677181" "STORET-738677182"
## [4] "STORET-738677872" "STORET-738678004" "STORET-738678005"
## [7] "STORET-738678052" "STORET-738678053" "STORET-738678066"
## [10] "STORET-738678728" "STORET-738678722" "STORET-738679070"
## [13] "STORET-738679883" "STORET-738679884" "STORET-738680635"
## [16] "STORET-738681838" "STORET-738681839" "STORET-738681567"
## [19] "STORET-738681566" "STORET-738681582" "STORET-738681583"
## [22] "STORET-738681742" "STORET-738681741" "STORET-738682016"
## [25] "STORET-738683894" "STORET-738683895" "STORET-738684233"
## [28] "STORET-738684234" "STORET-738684637" "STORET-738684635"
## [31] "STORET-738684636" "STORET-738684858" "STORET-738684859"
## [34] "STORET-738685617" "STORET-738685618" "STORET-738685619"
## [37] "STORET-738687020" "STORET-738687096" "STORET-738687162"
## [40] "STORET-738688568" "STORET-738689666" "STORET-738689761"
## [43] "STORET-738690356" "STORET-738690360" "STORET-738690508"
## [46] "STORET-738690893" "STORET-738691579" "STORET-738691571"
## [49] "STORET-738691593" "STORET-738691651" "STORET-738691793"
## [52] "STORET-738691845" "STORET-738691902" "STORET-738691903"
## [55] "STORET-738691940" "STORET-738692026" "STORET-738692088"
## [58] "STORET-738692119" "STORET-738692301" "Orphan"
## [61] "STORET-954146116" "STORET-954146117" "STORET-954146118"
## [64] "STORET-954146119" "STORET-954146120" "STORET-954146124"
## [67] "STORET-954146125" "STORET-954146126" "STORET-954146127"
## [70] "STORET-954146129" "STORET-954146163" "STORET-954146164"
## [73] "STORET-954146165" "STORET-954146167" "STORET-954146168"
## [76] "STORET-974501819" "STORET-974501818" "STORET-974501815"
## [79] "STORET-974501820" "STORET-974501816" "STORET-974495554"
## [82] "STORET-974498873" "STORET-974498871" "STORET-974498869"
## [85] "STORET-974498870" "STORET-974498874" "STORET-974510302"
## [88] "STORET-974510305" "STORET-974510304" "STORET-974510301"
## [91] "STORET-974510303" "STORET-974508583" "STORET-974508582"
## [94] "STORET-974502340" "STORET-974502342" "STORET-974502341"
## [97] "STORET-974502344" "STORET-974502345" "STORET-974502192"
## [100] "STORET-974502193" "STORET-974502196" "STORET-974502198"
## [103] "STORET-974502199" "STORET-974506891" "STORET-974504800"
## [106] "STORET-974504801" "STORET-974504802" "STORET-974504803"
## [109] "STORET-974504805" "STORET-974506248" "STORET-974506249"
## [112] "STORET-974506251" "STORET-974506252" "STORET-974506253"
## [115] "STORET-974512254" "STORET-974512260" "STORET-974512256"
## [118] "STORET-974512258" "STORET-974512261" "STORET-974515119"
## [121] "STORET-974515115" "STORET-974515120" "STORET-974515117"
## [124] "STORET-974515118" "STORET-974515122" "STORET-974517448"
## [127] "STORET-974514935" "STORET-974514940" "STORET-974514939"
## [130] "STORET-974514941" "STORET-974514938"
# Filter df to include only unique values that are paired replicate samples (parent-result and child-replicate).
# Exclude NAs
TADAProfileClean3b <- TADAProfileClean3b[!is.na(TADAProfileClean3b$TADA.ReplicateSampleID), ]
# Exclude orphans
TADAProfileClean3b <- dplyr::filter(TADAProfileClean3b, TADA.ReplicateSampleID != "Orphan")
# Review unique values in TADA.ReplicateSampleID
unique(TADAProfileClean3b$TADA.ReplicateSampleID)## [1] "STORET-738677181" "STORET-738677182" "STORET-738677872"
## [4] "STORET-738678004" "STORET-738678005" "STORET-738678052"
## [7] "STORET-738678053" "STORET-738678066" "STORET-738678728"
## [10] "STORET-738678722" "STORET-738679070" "STORET-738679883"
## [13] "STORET-738679884" "STORET-738680635" "STORET-738681838"
## [16] "STORET-738681839" "STORET-738681567" "STORET-738681566"
## [19] "STORET-738681582" "STORET-738681583" "STORET-738681742"
## [22] "STORET-738681741" "STORET-738682016" "STORET-738683894"
## [25] "STORET-738683895" "STORET-738684233" "STORET-738684234"
## [28] "STORET-738684637" "STORET-738684635" "STORET-738684636"
## [31] "STORET-738684858" "STORET-738684859" "STORET-738685617"
## [34] "STORET-738685618" "STORET-738685619" "STORET-738687020"
## [37] "STORET-738687096" "STORET-738687162" "STORET-738688568"
## [40] "STORET-738689666" "STORET-738689761" "STORET-738690356"
## [43] "STORET-738690360" "STORET-738690508" "STORET-738690893"
## [46] "STORET-738691579" "STORET-738691571" "STORET-738691593"
## [49] "STORET-738691651" "STORET-738691793" "STORET-738691845"
## [52] "STORET-738691902" "STORET-738691903" "STORET-738691940"
## [55] "STORET-738692026" "STORET-738692088" "STORET-738692119"
## [58] "STORET-738692301" "STORET-954146116" "STORET-954146117"
## [61] "STORET-954146118" "STORET-954146119" "STORET-954146120"
## [64] "STORET-954146124" "STORET-954146125" "STORET-954146126"
## [67] "STORET-954146127" "STORET-954146129" "STORET-954146163"
## [70] "STORET-954146164" "STORET-954146165" "STORET-954146167"
## [73] "STORET-954146168" "STORET-974501819" "STORET-974501818"
## [76] "STORET-974501815" "STORET-974501820" "STORET-974501816"
## [79] "STORET-974495554" "STORET-974498873" "STORET-974498871"
## [82] "STORET-974498869" "STORET-974498870" "STORET-974498874"
## [85] "STORET-974510302" "STORET-974510305" "STORET-974510304"
## [88] "STORET-974510301" "STORET-974510303" "STORET-974508583"
## [91] "STORET-974508582" "STORET-974502340" "STORET-974502342"
## [94] "STORET-974502341" "STORET-974502344" "STORET-974502345"
## [97] "STORET-974502192" "STORET-974502193" "STORET-974502196"
## [100] "STORET-974502198" "STORET-974502199" "STORET-974506891"
## [103] "STORET-974504800" "STORET-974504801" "STORET-974504802"
## [106] "STORET-974504803" "STORET-974504805" "STORET-974506248"
## [109] "STORET-974506249" "STORET-974506251" "STORET-974506252"
## [112] "STORET-974506253" "STORET-974512254" "STORET-974512260"
## [115] "STORET-974512256" "STORET-974512258" "STORET-974512261"
## [118] "STORET-974515119" "STORET-974515115" "STORET-974515120"
## [121] "STORET-974515117" "STORET-974515118" "STORET-974515122"
## [124] "STORET-974517448" "STORET-974514935" "STORET-974514940"
## [127] "STORET-974514939" "STORET-974514941" "STORET-974514938"Now, let’s remove QC samples/measurements from the dataframe.
# Remove flagged QC samples using the TADA_FindQCActivities function:
TADAProfileClean4 <- TADA_FindQCActivities(TADAProfileClean3,
clean = TRUE
)
# regenerate table and pie chart
TADA_FieldValuesTable(TADAProfileClean4, "ActivityTypeCode")## Value Count
## 1 Field Msr/Obs 14457
## 2 Sample-Routine 3127
TADA_FieldValuesPie(TADAProfileClean4, "ActivityTypeCode")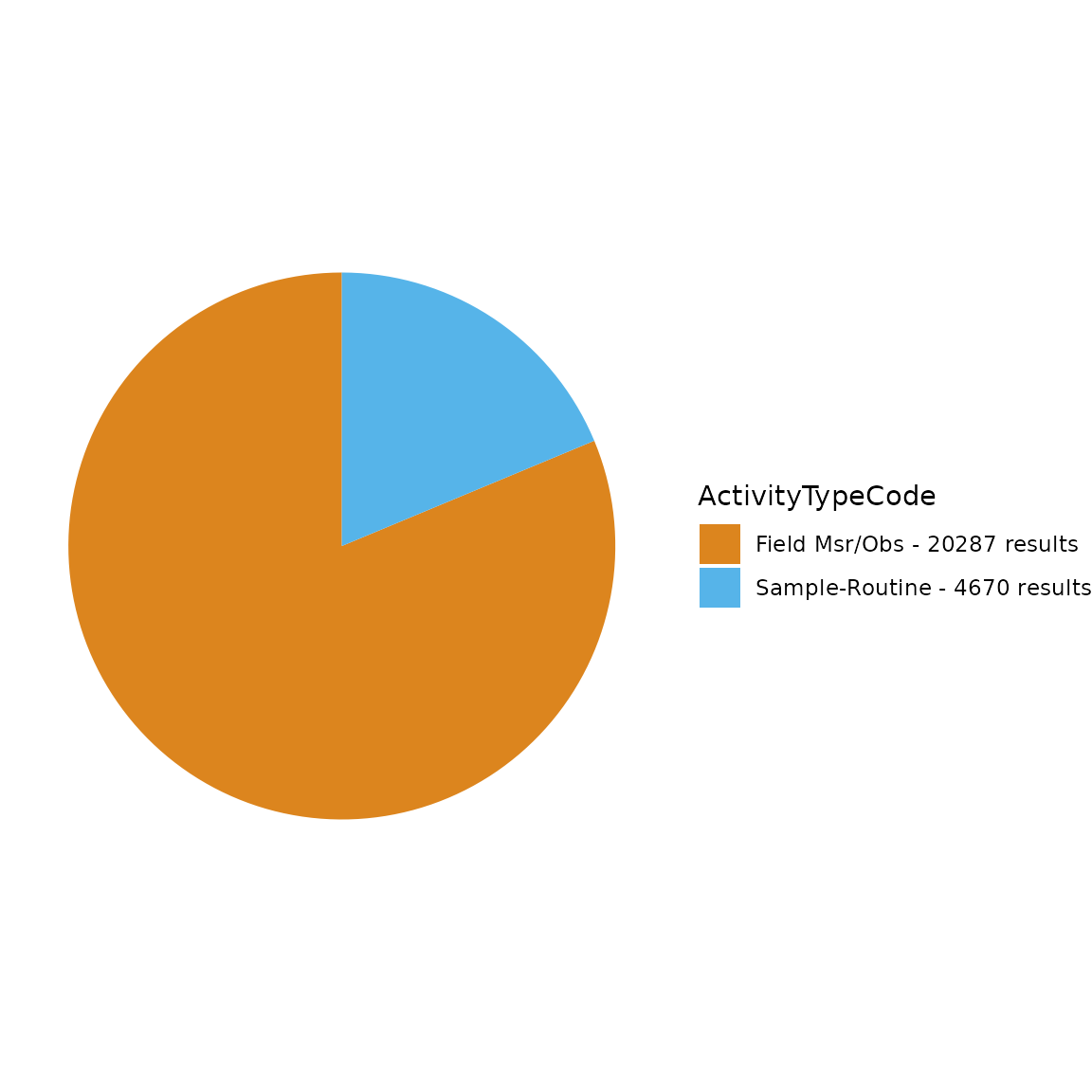
We’ve completed our review of the ActivityTypeCode.
rm(TADAProfileClean3, TADAProfileClean3a, TADAProfileClean3b)Now, let’s move on to a different field and see if there are any values that we want to remove.
In this next example, there are multiple MeasureQualifierCode values to review.
TADA_FieldValuesPie(TADAProfileClean4, "MeasureQualifierCode")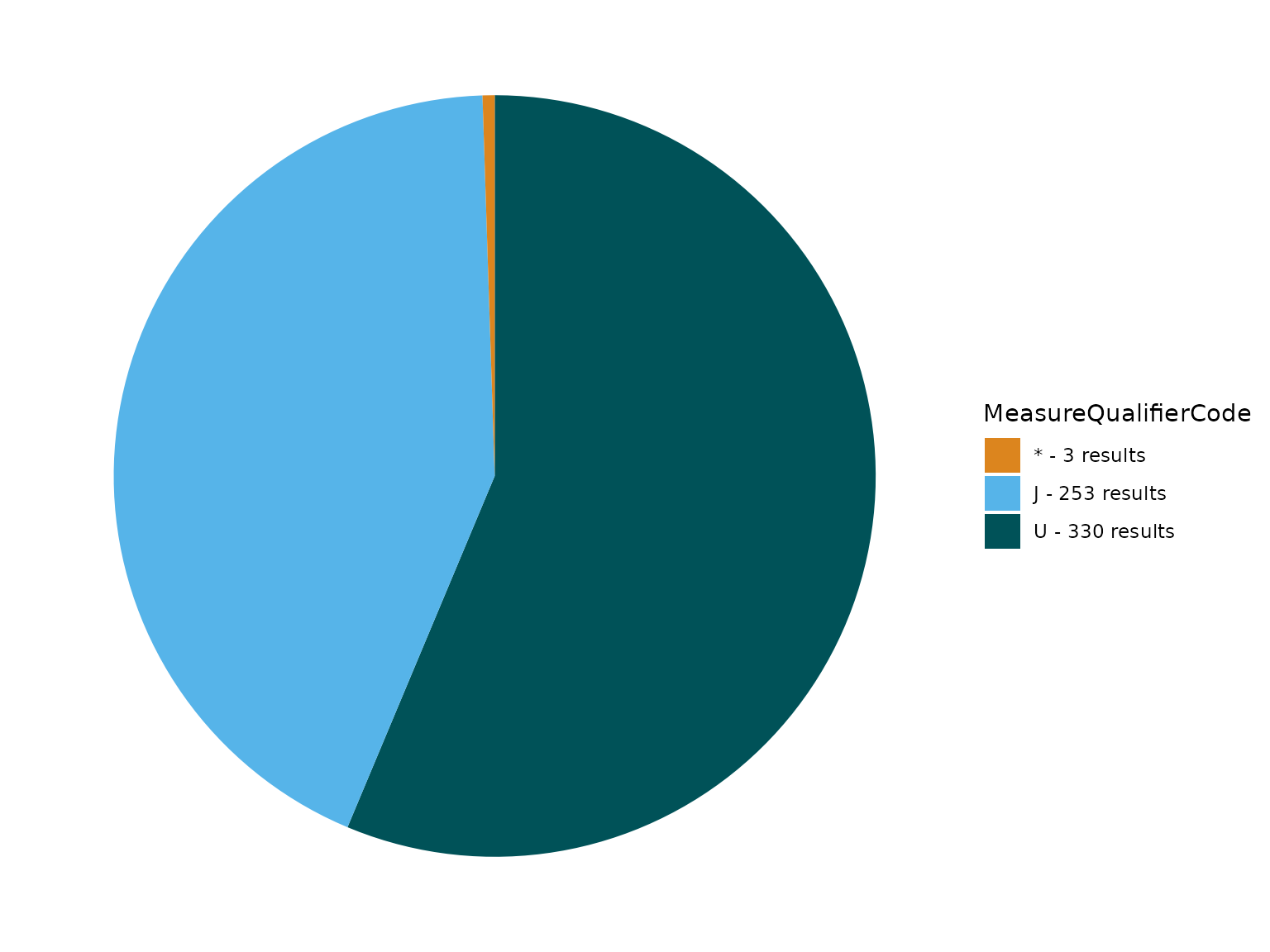
MeasureQualifierCode definitions are available here.
In this example, we show how to use the function TADA_FlagMeasureQualifierCode to add MeasureQualifierCode definitions and flag and/or remove rows with specific codes under MeasureQualifierCode that are categorized as “SUSPECT”.
See ?TADA_FlagMeasureQualifierCode for more information.
# flag only
Review_TADAProfileClean4 <- TADA_FlagMeasureQualifierCode(TADAProfileClean4,
clean = FALSE,
flaggedonly = TRUE,
define = TRUE
)
# Review_TADAProfileClean4 is empty because we did not find any Suspect samples
TADAProfileClean4 <- TADA_FlagMeasureQualifierCode(TADAProfileClean4,
clean = TRUE
)
# regenerate table and pie chart
TADA_FieldValuesPie(TADAProfileClean4, field = "TADA.MeasureQualifierCode.Def")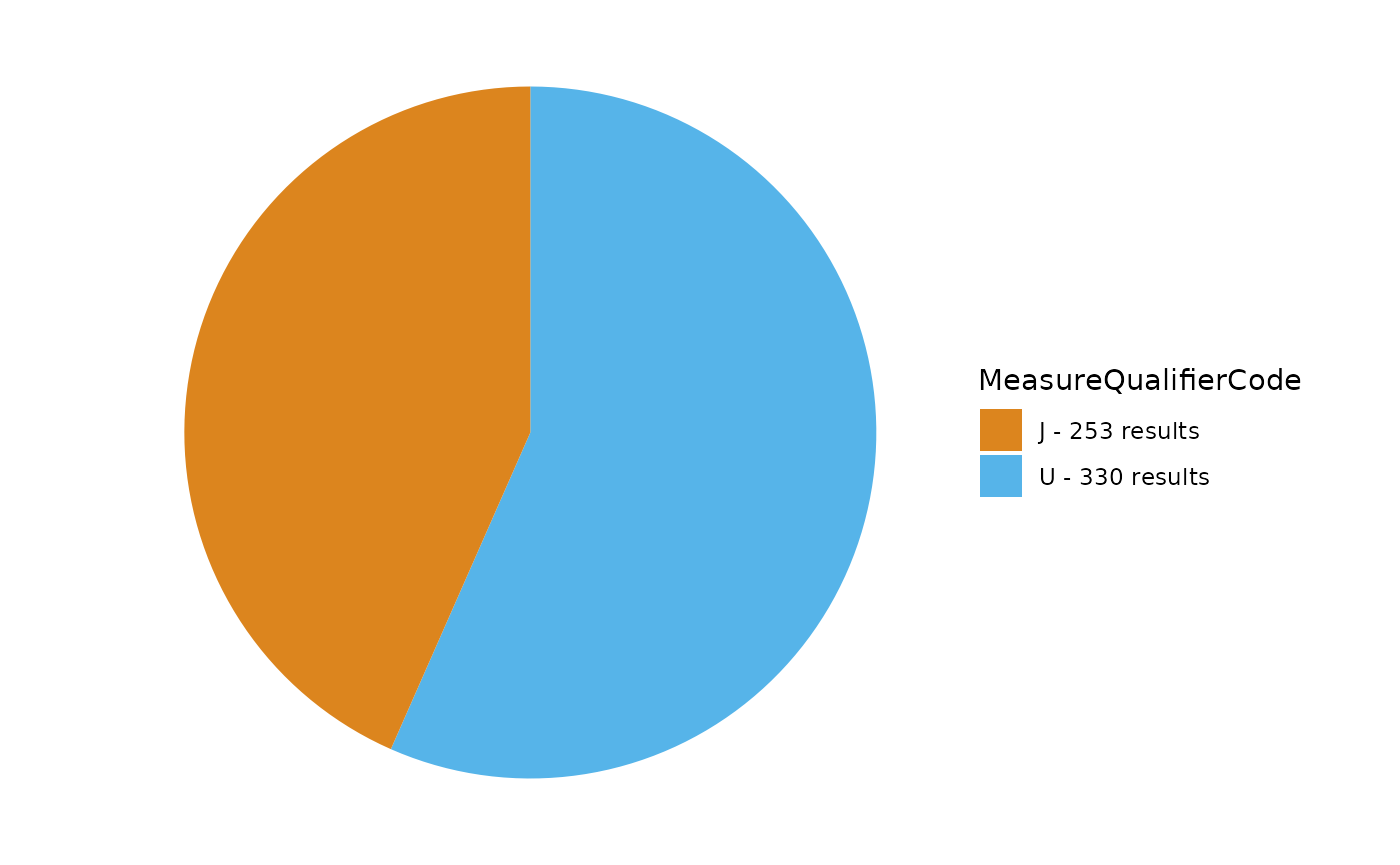
rm(Review_TADAProfileClean4)Censored data
Censored data are measurements for which the true value is not known, but we can estimate the value based on lower or upper detection conditions and limit types. TADA fills missing TADA.ResultMeasureValue and TADA.ResultMeasure.MeasureUnitCode values with values and units from TADA.DetectionQuantitationLimitMeasure.MeasureValue and TADA.DetectionQuantitationLimitMeasure.MeasureUnitCode, respectively, using the TADA_IDCensoredData function.
- TADA_IDCensoredData - categorizes detection limit data and identifies mismatches in result detection condition and result detection limit type. This function runs within the TADA_SimpleCensoredMethods function.
In other words, detection limit information is copied and pasted into the result value column when the original value is NA and detection limit information is available. The two columns TADA focuses on to define and flag censored data are ResultDetectionConditionText and DetectionQuantitationLimitTypeName.
The TADA package currently has functions that summarize censored data incidence in the dataset and perform simple substitutions of censored data values, including x times the detection limit and random selection of a value between 0 and the detection limit. The user may specify the methods used for non-detects and over-detects separately in the input to the TADA_SimpleCensoredMethods function.
All censored data functions depend first on the TADA_IDCensoredData utility function, which assigns a TADA.CensoredData.Flag to all data records and identifies over-detects from non-detects using the ResultDetectionConditionText and DetectionQuantitationLimitTypeName. This utility function is automatically run within the TADA_DataRetrieval function and produces the TADA.CensoredData.Flag column. All records receive one of the following classifications: - Uncensored - Not filled with detection limit value; a detection. - Non-Detect - Left-censored - Over-Detect - Right-censored - Other Condition/Limit Populated - detection condition or limit type are ambiguous or not associated with a lower/upper detection limit. - Conflict between Condition and Limit - detection condition and limit type for a single record do not agree, e.g. one suggests over-detect and the other suggests non-detect. - Detection condition or detection limit is not documented in TADA reference tables. - detection condition or limit type is not characterized in the TADA reference tables, which are based on WQX domain tables. - Detection condition is missing and required for censored data ID. - Result needs more information before being categorized.
The TADA_SimpleCensoredMethods function also adds a TADA.MeasureQualifierCode.Def column which contains the MeasureQualifierCode concatenated with the WQX definition for each qualifier code. This provides additional information to the user which may assist in deciding which records to retain for analysis.
The next step we take in this example is to perform simple conversions to the censored data in the dataset: we keep over-detects as is (no conversion made) and convert non-detect values to 0.5 times the detection limit (half the detection limit). Please review ?TADA_Stats and ?TADA_SimpleCensoredMethods for more information.
TADAProfileClean4 <- TADA_SimpleCensoredMethods(TADAProfileClean4,
nd_method = "multiplier",
nd_multiplier = 0.5,
od_method = "as-is",
od_multiplier = "null"
)Next, review unique values within the TADA.CensoredData.Flag, DetectionQuantitationLimitTypeName, and ResultDetectionConditionText columns.
# review unique values
unique(TADAProfileClean4$TADA.CensoredData.Flag)## [1] "Uncensored" "Non-Detect"
unique(TADAProfileClean4$DetectionQuantitationLimitTypeName)## [1] "Lower Reporting Limit" NA
## [3] "Method Detection Level" "Practical Quantitation Limit"
## [5] "Upper Quantitation Limit"
unique(TADAProfileClean4$ResultDetectionConditionText)## [1] "Not Detected at Reporting Limit" NA
## [3] "Present Below Quantification Limit" "Not Detected"Also, review the TADA.ResultMeasureValueDataTypes.Flag to see if any NAs or NDs (non-detects) remain.
unique(TADAProfileClean4$TADA.ResultMeasureValueDataTypes.Flag)## [1] "Coerced to NA"
## [2] "Numeric"
## [3] "Result Value/Unit Estimated from Detection Limit"
## [4] "Text"Count how many NAs remain in the TADA.ResultMeasureValue.
## [1] 903Filter down to only include data that is numeric in the “TADA.ResultMeasureValue” column. This removes data where the TADA.ResultMeasureValueDataTypes.Flag = “Text” or “NA - Not Available”.
TADAProfileClean5 <- TADA_ConvertSpecialChars(TADAProfileClean4, col = "TADA.ResultMeasureValue", clean = TRUE)Double check to make sure no NAs or NDs remain.
unique(TADAProfileClean5$TADA.ResultMeasureValueDataTypes.Flag)## [1] "Numeric"
## [2] "Result Value/Unit Estimated from Detection Limit"## [1] 903## [1] 0
rm(TADAProfileClean4)Convert synonymous characteristic, fraction, speciation, and unit values to a consistent convention based on user-defined/TADA standards
The TADA_GetSynonymRef function generates a synonym reference table that is specific to the input dataframe. Users can review how their input data relates to standard TADA values for the following elements:
TADA.CharacteristicName
TADA.ResultSampleFractionText
TADA.MethodSpeciationName
TADA.ResultMeasure.MeasureUnitCode
Users can also edit the reference file to meet their needs if desired. The download argument can be used to save the harmonization file to your current working directory when download = TRUE, the default is download = FALSE.
The TADA_HarmonizeSynonyms function then compares the input dataframe to the TADA Synonym Reference Table and makes conversions where target characteristics/fractions/speciations/units are provided. This function also appends a column called TADA.Harmonized.Flag, indicating which results had metadata changed/converted in this function. The purpose of this function is to make similar data consistent and therefore easier to compare and analyze.
Here are some examples of how the TADA_HarmonizeSynonyms function can be used:
TADA.ResultSampleFractionText specifies forms of constituents. In some cases, a single TADA.CharacteristicName will have both “Total” and “Dissolved” forms specified, which should not be combined. In these cases, each TADA.CharacteristicName and TADA.ResultSampleFractionText combination is given a different identifier. This identifier can be used later on to identify comparable data groups for calculating statistics and creating figures for each combination.
Some variables have different names but represent the same constituent (e.g., “Total Kjeldahl nitrogen (Organic N & NH3)” and “Kjeldahl nitrogen”). The TADA_HarmonizeSynonyms function gives a consistent name (and identifier) to synonyms.
UniqueHarmonizationRef <- TADA_GetSynonymRef(TADAProfileClean5)
TADAProfileClean5 <- TADA_HarmonizeSynonyms(TADAProfileClean5,
ref = UniqueHarmonizationRef
)
rm(UniqueHarmonizationRef)Total Nitrogen and Total Phosphorus Calculations
This section covers summing nutrient subspecies to estimate total nitrogen and phosphorus. This can be a challenging endeavor because some subspecies/compounds overlap in total nutrient calculations. Thus, TADA_CalculateTotalNP uses the Nutrient Aggregation logic to add together specific subspecies to obtain a total. TADA adds one more equation to the mix: total particulate nitrogen + total dissolved nitrogen. The function uses as many subspecies as possible to calculate a total for each given site, date, and depth group, but it will estimate total nitrogen with whatever subspecies are present. This function creates NEW total nutrient measurements (total nitrogen unfiltered as N and total phosphorus unfiltered as P) and adds them to the dataframe.
Users can use the default summation worksheet (see TADA_GetNutrientSummationRef) or customize it to suit their needs. The function also requires a daily aggregation value, either minimum, maximum, or mean. The default is ‘max’, which means that if multiple measurements of the same subspecies-fraction-speciation-unit occur on the same day at the same site and depth, the function will pick the maximum value to use in summation calculations.
TADAProfileClean6 <- TADA_CalculateTotalNP(TADAProfileClean5, daily_agg = "max")
rm(TADAProfileClean5)Parameter Level Filtering
In this section, you can select a single parameter, and review the unique values in specified fields. You may then choose to remove particular values by filtering.
To start, review the list of parameters in the dataframe using the TADA_FieldValuesTable function.
Enter ?TADA_FieldValuesTable into the console for more information.
TADA_FieldValuesTable(TADAProfileClean6, field = "TADA.CharacteristicName")## Value Count
## 1 DISSOLVED OXYGEN (DO) 3575
## 2 PH 3572
## 3 TEMPERATURE 3564
## 4 TURBIDITY 1229
## 5 TOTAL PHOSPHORUS, MIXED FORMS 771
## 6 DISSOLVED OXYGEN SATURATION 727
## 7 DEPTH 481
## 8 SALINITY 379
## 9 DEPTH, SECCHI DISK DEPTH 331
## 10 NITRATE 242
## 11 TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3) 242
## 12 CHLOROPHYLL A, CORRECTED FOR PHEOPHYTIN 231
## 13 TRANSPARENCY, SECCHI TUBE WITH DISK 212
## 14 TOTAL NITROGEN, MIXED FORMS 203
## 15 ESCHERICHIA COLI 160
## 16 CONDITION CLASS (DISSOLVED OXYGEN (DO)) 129
## 17 NITRITE 111
## 18 TOTAL SUSPENDED SOLIDS 111
## 19 AMMONIUM 93
## 20 DISSOLVED OXYGEN UPTAKE 82
## 21 ORTHOPHOSPHATE 82
## 22 NITRATE + NITRITE 71
## 23 APPARENT COLOR 49
## 24 CHLOROPHYLL A 48
## 25 COPPER 36
## 26 MERCURY 35
## 27 DEPTH, SNOW COVER 33
## 28 VOLATILE SUSPENDED SOLIDS 31
## 29 HARDNESS, CARBONATE 29
## 30 ZINC 28
## 31 NICKEL 26
## 32 IRON 24
## 33 COUNT 20
## 34 LEAD 19
## 35 BIOCHEMICAL OXYGEN DEMAND, STANDARD CONDITIONS 15
## 36 CHROMIUM 11
## 37 PERIPHYTON 7
## 38 MAGNESIUM 6
## 39 RADIUM-226 5
## 40 RADIUM-228 5
## 41 TRITIUM 5
## 42 ORGANIC CARBON 4Next, we can revisit the TADA_FieldCounts function at the characteristic level to review how many unique allowable values are included within each of the following fields:
ActivityCommentText
ActivityTypeCode
TADA.ActivityMediaName
ActivityMediaSubdivisionName
MeasureQualifierCode
MonitoringLocationTypeName
HydrologicCondition
HydrologicEvent
ResultStatusIdentifier
MethodQualifierTypeName
ResultCommentText
ResultLaboratoryCommentText
TADA.ResultMeasure.MeasureUnitCode
TADA.ResultSampleFractionText
ResultTemperatureBasisText
ResultValueTypeName
ResultWeightBasisText
SampleCollectionEquipmentName
LaboratoryName
MethodDescriptionText
ResultParticleSizeBasisText
SampleCollectionMethod.MethodIdentifier
SampleCollectionMethod.MethodIdentifierContext
SampleCollectionMethod.MethodName
DataQuality.BiasValue
MethodSpeciationName
ResultAnalyticalMethod.MethodName
ResultAnalyticalMethod.MethodIdentifier
ResultAnalyticalMethod.MethodIdentifierContext
AssemblageSampledName
DetectionQuantitationLimitTypeName
TADA_FieldCounts(TADAProfileClean6, display = "most", characteristicName = "TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)")## Fields Count
## 1 TADA.MonitoringLocationIdentifier 74
## 2 MonitoringLocationName 74
## 3 TADA.MonitoringLocationName 74
## 4 ResultCommentText 9
## 5 ProjectIdentifier 6
## 6 ProjectName 6
## 7 HUCEightDigitCode 6
## 8 SampleCollectionMethod.MethodIdentifier 4
## 9 SampleCollectionMethod.MethodName 4
## 10 SampleCollectionMethod.MethodDescriptionText 4
## 11 SampleCollectionEquipmentName 3
## 12 LaboratoryName 3
## 13 DetectionQuantitationLimitTypeName 3
## 14 MonitoringLocationDescriptionText 3
## 15 ProjectDescriptionText 3
## 16 QAPPApprovalAgencyName 3
## 17 OrganizationIdentifier 2
## 18 OrganizationFormalName 2
## 19 ActivityMediaSubdivisionName 2
## 20 ActivityRelativeDepthName 2
## 21 SampleCollectionMethod.MethodIdentifierContext 2
## 22 ResultStatusIdentifier 2
## 23 HorizontalCoordinateReferenceSystemDatumName 2
## 24 SamplingDesignTypeCode 2
## 25 TADA.MeasureQualifierCode.Def 2
## 26 TADA.MonitoringLocationTypeName 2
## 27 ActivityTypeCode 1
## 28 TADA.ActivityType.Flag 1
## 29 ActivityCommentText 1
## 30 SampleAquifer 1
## 31 HydrologicCondition 1
## 32 HydrologicEvent 1
## 33 ResultValueTypeName 1
## 34 USGSPCode 1
## 35 SubjectTaxonomicName 1
## 36 SampleTissueAnatomyName 1
## 37 ResultAnalyticalMethod.MethodIdentifier 1
## 38 ResultAnalyticalMethod.MethodIdentifierContext 1
## 39 ResultAnalyticalMethod.MethodName 1
## 40 ResultAnalyticalMethod.MethodDescriptionText 1
## 41 ResultLaboratoryCommentText 1
## 42 ProviderName 1
## 43 VerticalCoordinateReferenceSystemDatumName 1
## 44 AquiferName 1
## 45 LocalAqfrName 1
## 46 FormationTypeText 1
## 47 AquiferTypeName 1
## 48 TADA.ActivityMediaName 1
## 49 TADA.CharacteristicName 1
## 50 TADA.CharacteristicNameAssumptions 1
## 51 TADA.MethodSpeciationName 1
## 52 TADA.ResultSampleFractionText 1
## 53 TADA.ComparableDataIdentifier 1Selecting a parameter generates the list above, which is subset by the selected parameter. The list includes fields you may want to review, and the number of unique values in each field.
Next, choose a field from the list.
Review the WQX domain files for definitions: https://www.epa.gov/waterdata/storage-and-retrieval-and-water-quality-exchange-domain-services-and-downloads
Now, we’ll use TADA_FieldValuesTable and TADA_FieldValuesPie at the characteristic-level to review a column of interest.
# In this example we review values from the SampleCollectionMethod.MethodName field
TADA_FieldValuesTable(TADAProfileClean6, field = "SampleCollectionMethod.MethodName", characteristicName = "TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)")## Value Count
## 1 FDL QAPP 96
## 2 Standard Sampling Methods 86
## 3 Integrated Sampler 32
## 4 Hand Dipper 28
TADA_FieldValuesPie(TADAProfileClean6, field = "SampleCollectionMethod.MethodName", characteristicName = "TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)")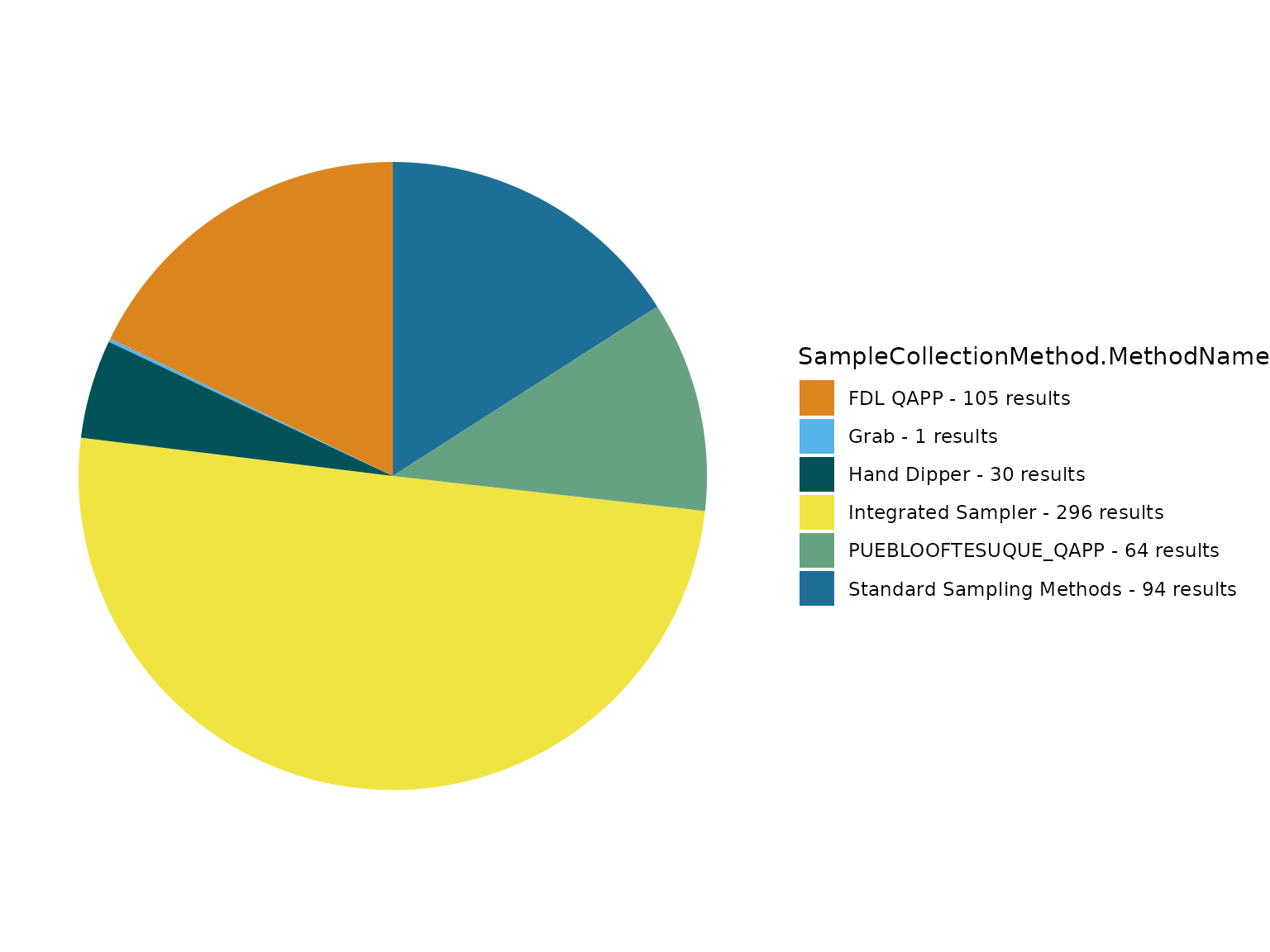
Review unique TADA.ComparableDataIdentifier’s.
unique(TADAProfileClean6$TADA.ComparableDataIdentifier)## [1] "DISSOLVED OXYGEN (DO)_NONE_NONE_MG/L"
## [2] "PH_NONE_NONE_NONE"
## [3] "TEMPERATURE_NONE_NONE_DEG C"
## [4] "TURBIDITY_NONE_NONE_NTU"
## [5] "AMMONIUM_UNFILTERED_AS N_MG/L"
## [6] "NITRATE_UNFILTERED_AS N_MG/L"
## [7] "ESCHERICHIA COLI_NONE_NONE_CFU/100ML"
## [8] "ESCHERICHIA COLI_UNFILTERED_NONE_CFU/100ML"
## [9] "NITRITE_UNFILTERED_AS N_MG/L"
## [10] "DEPTH_NONE_NONE_M"
## [11] "DISSOLVED OXYGEN SATURATION_NONE_NONE_%"
## [12] "SALINITY_NONE_NONE_PSS"
## [13] "BIOCHEMICAL OXYGEN DEMAND, STANDARD CONDITIONS_TOTAL_NONE_UG/L"
## [14] "CHROMIUM_TOTAL_NONE_UG/L"
## [15] "COPPER_TOTAL_NONE_UG/L"
## [16] "IRON_TOTAL_NONE_UG/L"
## [17] "HARDNESS, CARBONATE_TOTAL_NONE_UG/L"
## [18] "TURBIDITY_UNFILTERED_NONE_NTU"
## [19] "TOTAL PHOSPHORUS, MIXED FORMS_UNFILTERED_AS P_UG/L"
## [20] "CHLOROPHYLL A, CORRECTED FOR PHEOPHYTIN_SUSPENDED_NONE_UG/L"
## [21] "DEPTH, SECCHI DISK DEPTH_NONE_NONE_M"
## [22] "TRANSPARENCY, SECCHI TUBE WITH DISK_NONE_NONE_IN"
## [23] "DEPTH, SNOW COVER_NONE_NONE_IN"
## [24] "ORTHOPHOSPHATE_FILTERED_AS P_UG/L"
## [25] "CHLOROPHYLL A_FILTERED_AS CHLOROPHYLL A_UG/L"
## [26] "COUNT_NONE_NONE_COUNT"
## [27] "MAGNESIUM_DISSOLVED_NONE_UG/L"
## [28] "HARDNESS, CARBONATE_NONE_AS CACO3_UG/L"
## [29] "RADIUM-228_NONE_NONE_PCI/L"
## [30] "RADIUM-226_NONE_NONE_PCI/L"
## [31] "TRITIUM_NONE_NONE_PCI/L"
## [32] "IRON_DISSOLVED_NONE_UG/L"
## [33] "ZINC_DISSOLVED_NONE_UG/L"
## [34] "NITRATE + NITRITE_UNFILTERED_AS N_MG/L"
## [35] "TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)_UNFILTERED_AS N_MG/L"
## [36] "NITRATE + NITRITE_FILTERED_AS N_MG/L"
## [37] "TOTAL NITROGEN, MIXED FORMS_UNFILTERED_AS N_MG/L"
## [38] "TOTAL SUSPENDED SOLIDS_NON-FILTERABLE (PARTICLE)_NONE_UG/L"
## [39] "ORGANIC CARBON_DISSOLVED_NONE_UG/L"
## [40] "VOLATILE SUSPENDED SOLIDS_TOTAL_NONE_UG/L"
## [41] "CONDITION CLASS (DISSOLVED OXYGEN (DO))_NONE_NONE_%"
## [42] "DISSOLVED OXYGEN UPTAKE_NONE_NONE_UG/L"
## [43] "ORTHOPHOSPHATE_UNFILTERED_AS P_UG/L"
## [44] "NICKEL_TOTAL_NONE_UG/L"
## [45] "LEAD_TOTAL_NONE_UG/L"
## [46] "CHLOROPHYLL A_UNFILTERED_AS CHLOROPHYLL A_UG/L"
## [47] "ZINC_TOTAL_NONE_UG/L"
## [48] "APPARENT COLOR_TOTAL_NONE_PCU"
## [49] "MERCURY_TOTAL_NONE_UG/L"
## [50] "MERCURY_DISSOLVED_NONE_UG/L"
## [51] "PERIPHYTON_NONE_NONE_G/M2"Filter dataframe and generate scatterplots for each selected TADA.ComparableDataIdentifier:
TADAProfileClean6_filtered <- TADAProfileClean6[
TADAProfileClean6$TADA.ComparableDataIdentifier %in%
c(
"BIOCHEMICAL OXYGEN DEMAND, STANDARD CONDITIONS_TOTAL_NA_UG/L",
"CHEMICAL OXYGEN DEMAND_TOTAL_NA_UG/L",
"SULFATE_TOTAL_NA_UG/L",
"NICKEL_TOTAL_NA_UG/L",
"COPPER_TOTAL_NA_UG/L",
"ZINC_TOTAL_NA_UG/L",
"ORTHOPHOSPHATE_UNFILTERED_AS P_UG/L",
"SELENIUM_TOTAL_NA_UG/L",
"LEAD_TOTAL_NA_UG/L",
"TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)_UNFILTERED_AS N_MG/L",
"CHLORIDE_TOTAL_NA_UG/L",
"ARSENIC_TOTAL_NA_UG/L",
"CHROMIUM_TOTAL_NA_UG/L"
),
]
TADA_Scatterplot(TADAProfileClean6_filtered, id_cols = c("TADA.ComparableDataIdentifier"))## $`ORTHOPHOSPHATE UNFILTERED AS P UG/L`
##
## $`TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3) UNFILTERED AS N MG/L`Choose two from TADAProfileClean6 and generate scatterplot:
TADA_TwoCharacteristicScatterplot(TADAProfileClean6, id_cols = "TADA.ComparableDataIdentifier", groups = c("TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)_UNFILTERED_AS N_MG/L", "ORTHOPHOSPHATE_UNFILTERED_AS P_UG/L"))Now we will summarize results for a single comparable data group using the TADA.ComparableDataIdentifier (i.e., comparable characteristic, unit, speciation, and fraction combination) using TADA_Histogram and TADA_Boxplot. Note that users may generate a list output of multiple plots if their input dataset has more than one unique comparable data group.
# review TADA.ComparableDataIdentifier
unique(TADAProfileClean6$TADA.ComparableDataIdentifier)## [1] "DISSOLVED OXYGEN (DO)_NONE_NONE_MG/L"
## [2] "PH_NONE_NONE_NONE"
## [3] "TEMPERATURE_NONE_NONE_DEG C"
## [4] "TURBIDITY_NONE_NONE_NTU"
## [5] "AMMONIUM_UNFILTERED_AS N_MG/L"
## [6] "NITRATE_UNFILTERED_AS N_MG/L"
## [7] "ESCHERICHIA COLI_NONE_NONE_CFU/100ML"
## [8] "ESCHERICHIA COLI_UNFILTERED_NONE_CFU/100ML"
## [9] "NITRITE_UNFILTERED_AS N_MG/L"
## [10] "DEPTH_NONE_NONE_M"
## [11] "DISSOLVED OXYGEN SATURATION_NONE_NONE_%"
## [12] "SALINITY_NONE_NONE_PSS"
## [13] "BIOCHEMICAL OXYGEN DEMAND, STANDARD CONDITIONS_TOTAL_NONE_UG/L"
## [14] "CHROMIUM_TOTAL_NONE_UG/L"
## [15] "COPPER_TOTAL_NONE_UG/L"
## [16] "IRON_TOTAL_NONE_UG/L"
## [17] "HARDNESS, CARBONATE_TOTAL_NONE_UG/L"
## [18] "TURBIDITY_UNFILTERED_NONE_NTU"
## [19] "TOTAL PHOSPHORUS, MIXED FORMS_UNFILTERED_AS P_UG/L"
## [20] "CHLOROPHYLL A, CORRECTED FOR PHEOPHYTIN_SUSPENDED_NONE_UG/L"
## [21] "DEPTH, SECCHI DISK DEPTH_NONE_NONE_M"
## [22] "TRANSPARENCY, SECCHI TUBE WITH DISK_NONE_NONE_IN"
## [23] "DEPTH, SNOW COVER_NONE_NONE_IN"
## [24] "ORTHOPHOSPHATE_FILTERED_AS P_UG/L"
## [25] "CHLOROPHYLL A_FILTERED_AS CHLOROPHYLL A_UG/L"
## [26] "COUNT_NONE_NONE_COUNT"
## [27] "MAGNESIUM_DISSOLVED_NONE_UG/L"
## [28] "HARDNESS, CARBONATE_NONE_AS CACO3_UG/L"
## [29] "RADIUM-228_NONE_NONE_PCI/L"
## [30] "RADIUM-226_NONE_NONE_PCI/L"
## [31] "TRITIUM_NONE_NONE_PCI/L"
## [32] "IRON_DISSOLVED_NONE_UG/L"
## [33] "ZINC_DISSOLVED_NONE_UG/L"
## [34] "NITRATE + NITRITE_UNFILTERED_AS N_MG/L"
## [35] "TOTAL KJELDAHL NITROGEN (ORGANIC N & NH3)_UNFILTERED_AS N_MG/L"
## [36] "NITRATE + NITRITE_FILTERED_AS N_MG/L"
## [37] "TOTAL NITROGEN, MIXED FORMS_UNFILTERED_AS N_MG/L"
## [38] "TOTAL SUSPENDED SOLIDS_NON-FILTERABLE (PARTICLE)_NONE_UG/L"
## [39] "ORGANIC CARBON_DISSOLVED_NONE_UG/L"
## [40] "VOLATILE SUSPENDED SOLIDS_TOTAL_NONE_UG/L"
## [41] "CONDITION CLASS (DISSOLVED OXYGEN (DO))_NONE_NONE_%"
## [42] "DISSOLVED OXYGEN UPTAKE_NONE_NONE_UG/L"
## [43] "ORTHOPHOSPHATE_UNFILTERED_AS P_UG/L"
## [44] "NICKEL_TOTAL_NONE_UG/L"
## [45] "LEAD_TOTAL_NONE_UG/L"
## [46] "CHLOROPHYLL A_UNFILTERED_AS CHLOROPHYLL A_UG/L"
## [47] "ZINC_TOTAL_NONE_UG/L"
## [48] "APPARENT COLOR_TOTAL_NONE_PCU"
## [49] "MERCURY_TOTAL_NONE_UG/L"
## [50] "MERCURY_DISSOLVED_NONE_UG/L"
## [51] "PERIPHYTON_NONE_NONE_G/M2"
# filter dataframe to only "TOTAL PHOSPHORUS, MIXED FORMS"
TADAProfileCleanTP <- dplyr::filter(
TADAProfileClean6,
TADA.ComparableDataIdentifier == "ORTHOPHOSPHATE_UNFILTERED_AS P_UG/L"
)
# generate stats table
TADAProfileCleanTP_stats <- TADA_Stats(TADAProfileCleanTP)
TADAProfileCleanTP_stats## # A tibble: 1 × 23
## TADA.ComparableDataIdentif…¹ Location_Count Measurement_Count Non_Detect_Count
## <chr> <int> <int> <int>
## 1 ORTHOPHOSPHATE_UNFILTERED_A… 32 62 0
## # ℹ abbreviated name: ¹TADA.ComparableDataIdentifier
## # ℹ 19 more variables: Non_Detect_Pct <dbl>, Non_Detect_Lvls <int>,
## # Over_Detect_Count <int>, Over_Detect_Pct <dbl>, UpperFence <dbl>,
## # LowerFence <dbl>, Min <dbl>, Mean <dbl>, Max <dbl>, Percentile_5th <dbl>,
## # Percentile_10th <dbl>, Percentile_15th <dbl>, Percentile_25th <dbl>,
## # Percentile_50th_Median <dbl>, Percentile_75th <dbl>, Percentile_85th <dbl>,
## # Percentile_95th <dbl>, Percentile_98th <dbl>, ND_Estimation_Method <chr>
# generate a histogram
TP_Histogram <- TADA_Histogram(TADAProfileCleanTP,
id_cols =
"TADA.ComparableDataIdentifier"
)
# view histogram
TP_HistogramGenerate interactive box plot.
TP_Boxplot <- TADA_Boxplot(TADAProfileCleanTP,
id_cols =
"TADA.ComparableDataIdentifier"
)
TP_BoxplotRetain TADA Required Columns
Now we can review the “TADA” prefixed columns we have added to the data set. If we are satisfied with the conversions, filtering, flagging, etc. and the resulting “TADA” columns, we can use the TADA_RetainRequired function to remove any columns that are not required or used as filters in the TADA workflow. This reduces the size of the dataframe.
TADAProfileClean7 <- TADA_RetainRequired(TADAProfileClean6)TADA Shiny Application
Finally, take a look at an alternative workflow, TADA Shiny Module 1: Data Discovery and Cleaning. This is a Shiny application that runs many of the TADA functions covered in this document behind a graphical user interface. The shiny application queries the WQP, contains maps and data visualizations, flags suspect data results, handles censored data, and more. You can launch it using the code below.
DRAFT Module 1 is also currently hosted on the web with minimal server memory/storage allocated.
# download TADA Shiny repository
remotes::install_github("USEPA/TADAShiny",
ref = "develop",
dependencies = TRUE
)
# launch the app locally.
TADAShiny::run_app()Download this Article from GitHub
Go to: https://github.com/USEPA/EPATADA/blob/develop/vignettes/TADAModule1.Rmd